
Qwen3-TTS
Collection
7 items • Updated • 352
This repository contains the Qwen3-TTS-Tokenizer-12Hz, as presented in the paper Qwen3-TTS Technical Report.
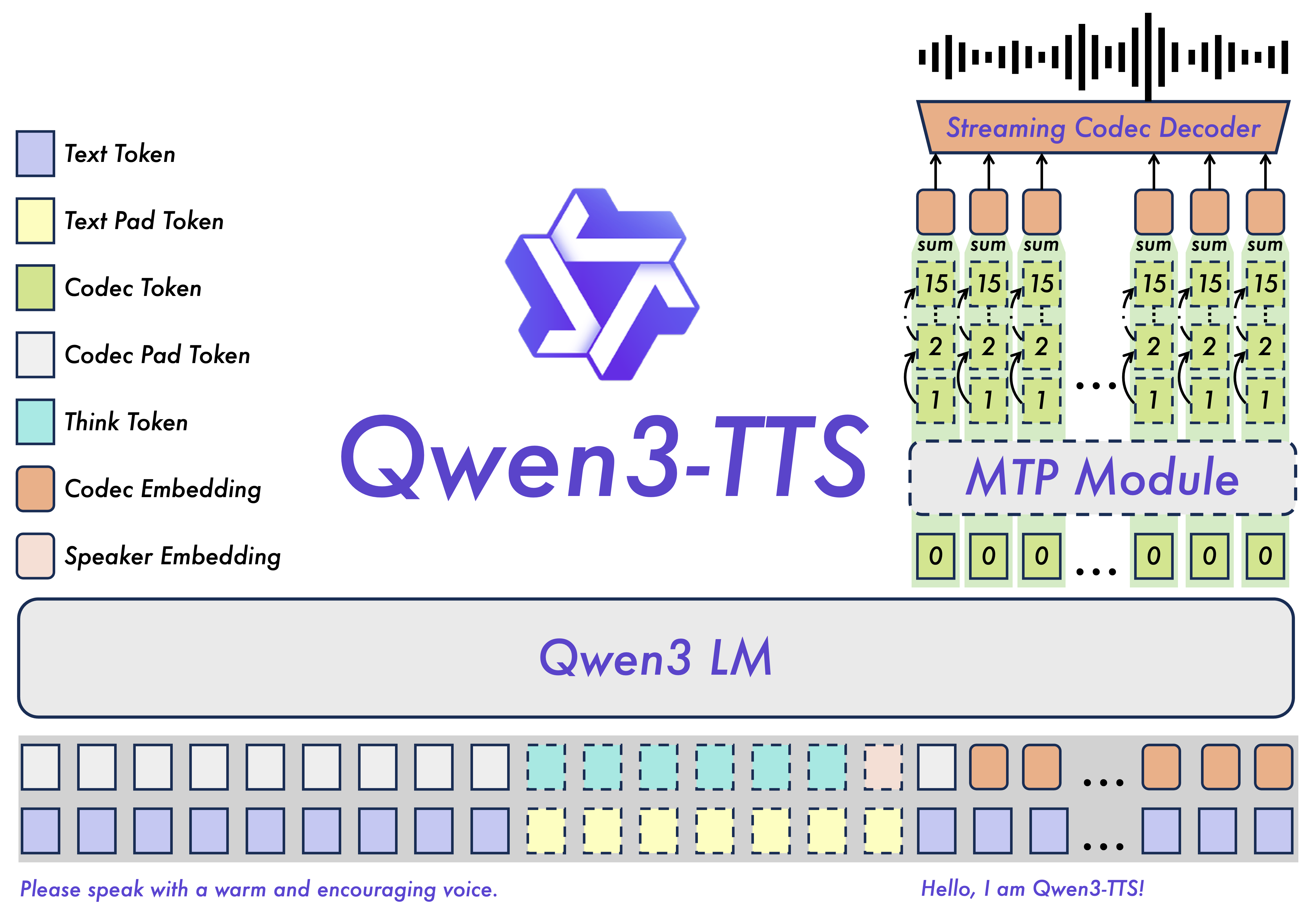
Qwen3-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet.
Install the qwen-tts Python package from PyPI:
pip install -U qwen-tts
You can encode audio into discrete tokens for storage or transport and decode them back into speech using the snippet below:
import soundfile as sf
from qwen_tts import Qwen3TTSTokenizer
tokenizer = Qwen3TTSTokenizer.from_pretrained(
"Qwen/Qwen3-TTS-Tokenizer-12Hz",
device_map="cuda:0",
)
# Encode audio from a URL (or local path)
enc = tokenizer.encode("https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-TTS-Repo/tokenizer_demo_1.wav")
# Decode codes back into waveforms
wavs, sr = tokenizer.decode(enc)
sf.write("decode_output.wav", wavs[0], sr)
Qwen3-TTS covers 10 major languages (Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian) as well as multiple dialectal voice profiles. Key features:
| Tokenizer Name | Description |
|---|---|
| Qwen3-TTS-Tokenizer-12Hz | The Qwen3-TTS-Tokenizer-12Hz model which can encode the input speech into codes and decode them back into speech. |
For detailed evaluation results on speech generation consistency, speaker similarity, and tokenizer benchmarks (ASR tasks, PESQ, STOI, UTMOS), please refer to the technical report or the GitHub repository.
@article{Qwen3-TTS,
title={Qwen3-TTS Technical Report},
author={Hangrui Hu and Xinfa Zhu and Ting He and Dake Guo and Bin Zhang and Xiong Wang and Zhifang Guo and Ziyue Jiang and Hongkun Hao and Zishan Guo and Xinyu Zhang and Pei Zhang and Baosong Yang and Jin Xu and Jingren Zhou and Junyang Lin},
journal={arXiv preprint arXiv:2601.15621},
year={2026}
}