
Multi-Dimensional Gender Bias Classification
Paper • 2005.00614 • Published
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 2.8B | node_id stringlengths 18 32 | number int64 1 7.38k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments sequencelengths 0 0 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[us] | author_association stringclasses 4
values | sub_issues_summary dict | active_lock_reason float64 | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | draft float64 0 1 ⌀ | pull_request dict | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/7378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7378/comments | https://api.github.com/repos/huggingface/datasets/issues/7378/events | https://github.com/huggingface/datasets/issues/7378 | 2,802,957,388 | I_kwDODunzps6nEbxM | 7,378 | Allow pushing config version to hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/129072?v=4",
"events_url": "https://api.github.com/users/momeara/events{/privacy}",
"followers_url": "https://api.github.com/users/momeara/followers",
"following_url": "https://api.github.com/users/momeara/following{/other_user}",
"gists_url": "https://... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2025-01-21T22:35:07 | 2025-01-21T22:35:07 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Feature request
Currently, when datasets are created, they can be versioned by passing the `version` argument to `load_dataset(...)`. For example creating `outcomes.csv` on the command line
```
echo "id,value\n1,0\n2,0\n3,1\n4,1\n" > outcomes.csv
```
and creating it
```
import datasets
dataset = datasets.load_dat... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7378/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7377/comments | https://api.github.com/repos/huggingface/datasets/issues/7377/events | https://github.com/huggingface/datasets/issues/7377 | 2,802,723,285 | I_kwDODunzps6nDinV | 7,377 | Support for sparse arrays with the Arrow Sparse Tensor format? | {
"avatar_url": "https://avatars.githubusercontent.com/u/3231217?v=4",
"events_url": "https://api.github.com/users/JulesGM/events{/privacy}",
"followers_url": "https://api.github.com/users/JulesGM/followers",
"following_url": "https://api.github.com/users/JulesGM/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2025-01-21T20:14:35 | 2025-01-21T20:17:17 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Feature request
AI in biology is becoming a big thing. One thing that would be a huge benefit to the field that Huggingface Datasets doesn't currently have is native support for **sparse arrays**.
Arrow has support for sparse tensors.
https://arrow.apache.org/docs/format/Other.html#sparse-tensor
It would be ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7377/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7377/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7376/comments | https://api.github.com/repos/huggingface/datasets/issues/7376/events | https://github.com/huggingface/datasets/pull/7376 | 2,802,621,104 | PR_kwDODunzps6IiO9j | 7,376 | [docs] uv install | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [] | 2025-01-21T19:15:48 | 2025-01-21T19:39:29 | 1970-01-01T00:00:00 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Proposes adding uv to installation docs (see Slack thread [here](https://huggingface.slack.com/archives/C01N44FJDHT/p1737377177709279) for more context) if you're interested! | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7376/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7376/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7376.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7376",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7376.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7376"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/7375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7375/comments | https://api.github.com/repos/huggingface/datasets/issues/7375/events | https://github.com/huggingface/datasets/issues/7375 | 2,800,609,218 | I_kwDODunzps6m7efC | 7,375 | vllm批量推理报错 | {
"avatar_url": "https://avatars.githubusercontent.com/u/51228154?v=4",
"events_url": "https://api.github.com/users/YuShengzuishuai/events{/privacy}",
"followers_url": "https://api.github.com/users/YuShengzuishuai/followers",
"following_url": "https://api.github.com/users/YuShengzuishuai/following{/other_user}"... | [] | open | false | null | [] | null | [] | 2025-01-21T03:22:23 | 2025-01-21T03:22:23 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug

### Steps to reproduce the bug
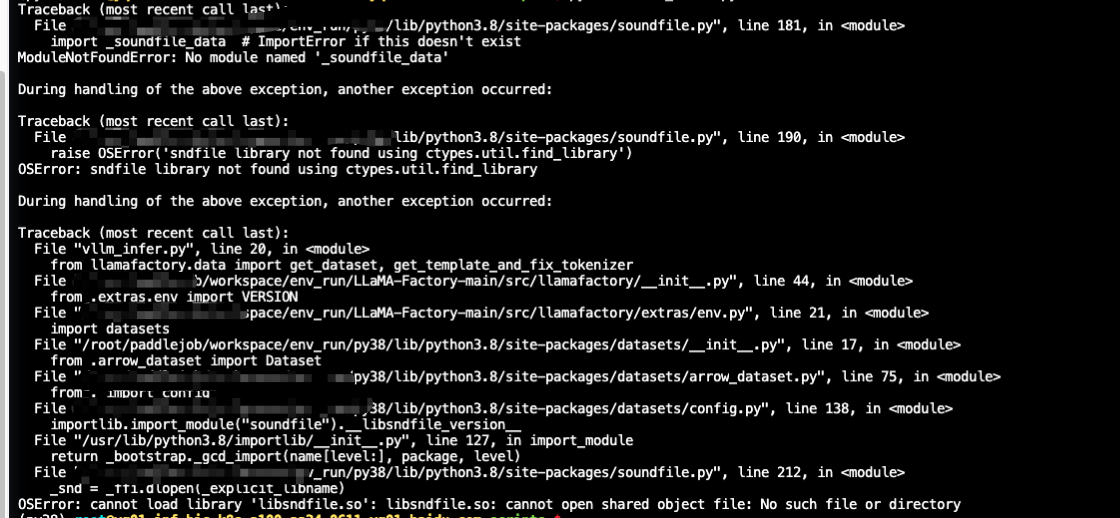
### Expected behavior
 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7374/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7374.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7374",
"merged_at": "2025-01-16T18:26:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7374.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7373/comments | https://api.github.com/repos/huggingface/datasets/issues/7373/events | https://github.com/huggingface/datasets/issues/7373 | 2,793,237,139 | I_kwDODunzps6mfWqT | 7,373 | Excessive RAM Usage After Dataset Concatenation concatenate_datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [] | 2025-01-16T16:33:10 | 2025-01-17T08:05:22 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
When loading a dataset from disk, concatenating it, and starting the training process, the RAM usage progressively increases until the kernel terminates the process due to excessive memory consumption.
https://github.com/huggingface/datasets/issues/2276
### Steps to reproduce the bug
```
rom da... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7373/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7373/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7372/comments | https://api.github.com/repos/huggingface/datasets/issues/7372/events | https://github.com/huggingface/datasets/issues/7372 | 2,791,760,968 | I_kwDODunzps6mZuRI | 7,372 | Inconsistent Behavior Between `load_dataset` and `load_from_disk` When Loading Sharded Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/38203359?v=4",
"events_url": "https://api.github.com/users/gaohongkui/events{/privacy}",
"followers_url": "https://api.github.com/users/gaohongkui/followers",
"following_url": "https://api.github.com/users/gaohongkui/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [] | 2025-01-16T05:47:20 | 2025-01-16T05:47:20 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Description
I encountered an inconsistency in behavior between `load_dataset` and `load_from_disk` when loading sharded datasets. Here is a minimal example to reproduce the issue:
#### Code 1: Using `load_dataset`
```python
from datasets import Dataset, load_dataset
# First save with max_shard_size=10
Dataset.fr... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7372/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7372/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7371/comments | https://api.github.com/repos/huggingface/datasets/issues/7371/events | https://github.com/huggingface/datasets/issues/7371 | 2,790,549,889 | I_kwDODunzps6mVGmB | 7,371 | 500 Server error with pushing a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/7677814?v=4",
"events_url": "https://api.github.com/users/martinmatak/events{/privacy}",
"followers_url": "https://api.github.com/users/martinmatak/followers",
"following_url": "https://api.github.com/users/martinmatak/following{/other_user}",
"gists_ur... | [] | open | false | null | [] | null | [] | 2025-01-15T18:23:02 | 2025-01-15T20:06:05 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
Suddenly, I started getting this error message saying it was an internal error.
`Error creating/pushing dataset: 500 Server Error: Internal Server Error for url: https://huggingface.co/api/datasets/ll4ma-lab/grasp-dataset/commit/main (Request ID: Root=1-6787f0b7-66d5bd45413e481c4c2fb22d;670d04ff-... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7371/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7370 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7370/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7370/comments | https://api.github.com/repos/huggingface/datasets/issues/7370/events | https://github.com/huggingface/datasets/pull/7370 | 2,787,972,786 | PR_kwDODunzps6HwAu7 | 7,370 | Support faster processing using pandas or polars functions in `IterableDataset.map()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [] | 2025-01-14T18:14:13 | 2025-01-14T18:30:13 | 1970-01-01T00:00:00 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Allow super fast processing using pandas or polars functions in `IterableDataset.map()` by adding support to pandas and polars formatting in `IterableDataset`
```python
import polars as pl
from datasets import Dataset
ds = Dataset.from_dict({"i": range(10)}).to_iterable_dataset()
ds = ds.with_format("polars")
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7370/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7370/timeline | null | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7370.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7370",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7370.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7370"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/7369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7369/comments | https://api.github.com/repos/huggingface/datasets/issues/7369/events | https://github.com/huggingface/datasets/issues/7369 | 2,787,193,238 | I_kwDODunzps6mITGW | 7,369 | Importing dataset gives unhelpful error message when filenames in metadata.csv are not found in the directory | {
"avatar_url": "https://avatars.githubusercontent.com/u/38278139?v=4",
"events_url": "https://api.github.com/users/svencornetsdegroot/events{/privacy}",
"followers_url": "https://api.github.com/users/svencornetsdegroot/followers",
"following_url": "https://api.github.com/users/svencornetsdegroot/following{/oth... | [] | open | false | null | [] | null | [] | 2025-01-14T13:53:21 | 2025-01-14T15:05:51 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
While importing an audiofolder dataset, where the names of the audiofiles don't correspond to the filenames in the metadata.csv, we get an unclear error message that is not helpful for the debugging, i.e.
```
ValueError: Instruction "train" corresponds to no data!
```
### Steps to reproduce the ... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7369/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7369/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7368/comments | https://api.github.com/repos/huggingface/datasets/issues/7368/events | https://github.com/huggingface/datasets/pull/7368 | 2,784,272,477 | PR_kwDODunzps6HjE97 | 7,368 | Add with_split to DatasetDict.map | {
"avatar_url": "https://avatars.githubusercontent.com/u/93233241?v=4",
"events_url": "https://api.github.com/users/jp1924/events{/privacy}",
"followers_url": "https://api.github.com/users/jp1924/followers",
"following_url": "https://api.github.com/users/jp1924/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [] | 2025-01-13T15:09:56 | 2025-01-22T02:32:11 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | #7356 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7368/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7368/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7368.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7368",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7368.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7368"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/7366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7366/comments | https://api.github.com/repos/huggingface/datasets/issues/7366/events | https://github.com/huggingface/datasets/issues/7366 | 2,781,522,894 | I_kwDODunzps6lyqvO | 7,366 | Dataset.from_dict() can't handle large dict | {
"avatar_url": "https://avatars.githubusercontent.com/u/164967134?v=4",
"events_url": "https://api.github.com/users/CSU-OSS/events{/privacy}",
"followers_url": "https://api.github.com/users/CSU-OSS/followers",
"following_url": "https://api.github.com/users/CSU-OSS/following{/other_user}",
"gists_url": "https... | [] | open | false | null | [] | null | [] | 2025-01-11T02:05:21 | 2025-01-11T02:05:21 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
I have 26,000,000 3-tuples. When I use Dataset.from_dict() to load, neither. py nor Jupiter notebook can run successfully. This is my code:
```
# len(example_data) is 26,000,000, 'diff' is a text
diff1_list = [example_data[i].texts[0] for i in range(len(example_data))]
diff2_list =... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7366/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7366/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7365/comments | https://api.github.com/repos/huggingface/datasets/issues/7365/events | https://github.com/huggingface/datasets/issues/7365 | 2,780,216,199 | I_kwDODunzps6ltruH | 7,365 | A parameter is specified but not used in datasets.arrow_dataset.Dataset.from_pandas() | {
"avatar_url": "https://avatars.githubusercontent.com/u/69003192?v=4",
"events_url": "https://api.github.com/users/NourOM02/events{/privacy}",
"followers_url": "https://api.github.com/users/NourOM02/followers",
"following_url": "https://api.github.com/users/NourOM02/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [] | 2025-01-10T13:39:33 | 2025-01-10T13:39:33 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
I am interested in creating train, test and eval splits from a pandas Dataframe, therefore I was looking at the possibilities I can follow. I noticed the split parameter and was hopeful to use it in order to generate the 3 at once, however, while trying to understand the code, i noticed that it ha... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7365/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7364/comments | https://api.github.com/repos/huggingface/datasets/issues/7364/events | https://github.com/huggingface/datasets/issues/7364 | 2,776,929,268 | I_kwDODunzps6lhJP0 | 7,364 | API endpoints for gated dataset access requests | {
"avatar_url": "https://avatars.githubusercontent.com/u/6140840?v=4",
"events_url": "https://api.github.com/users/jerome-white/events{/privacy}",
"followers_url": "https://api.github.com/users/jerome-white/followers",
"following_url": "https://api.github.com/users/jerome-white/following{/other_user}",
"gists... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 2025-01-09T06:21:20 | 2025-01-09T11:17:40 | 2025-01-09T11:17:20 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Feature request
I would like a programatic way of requesting access to gated datasets. The current solution to gain access forces me to visit a website and physically click an "agreement" button (as per the [documentation](https://huggingface.co/docs/hub/en/datasets-gated#access-gated-datasets-as-a-user)).
An i... | {
"avatar_url": "https://avatars.githubusercontent.com/u/6140840?v=4",
"events_url": "https://api.github.com/users/jerome-white/events{/privacy}",
"followers_url": "https://api.github.com/users/jerome-white/followers",
"following_url": "https://api.github.com/users/jerome-white/following{/other_user}",
"gists... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7364/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7364/timeline | null | not_planned | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7363/comments | https://api.github.com/repos/huggingface/datasets/issues/7363/events | https://github.com/huggingface/datasets/issues/7363 | 2,774,090,012 | I_kwDODunzps6lWUEc | 7,363 | ImportError: To support decoding images, please install 'Pillow'. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1394644?v=4",
"events_url": "https://api.github.com/users/jamessdixon/events{/privacy}",
"followers_url": "https://api.github.com/users/jamessdixon/followers",
"following_url": "https://api.github.com/users/jamessdixon/following{/other_user}",
"gists_ur... | [] | open | false | null | [] | null | [] | 2025-01-08T02:22:57 | 2025-01-16T08:54:47 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
Following this tutorial locally using a macboko and VSCode: https://huggingface.co/docs/diffusers/en/tutorials/basic_training
This line of code: for i, image in enumerate(dataset[:4]["image"]):
throws: ImportError: To support decoding images, please install 'Pillow'.
Pillow is installed.
###... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7363/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7362/comments | https://api.github.com/repos/huggingface/datasets/issues/7362/events | https://github.com/huggingface/datasets/issues/7362 | 2,773,731,829 | I_kwDODunzps6lU8n1 | 7,362 | HuggingFace CLI dataset download raises error | {
"avatar_url": "https://avatars.githubusercontent.com/u/3870355?v=4",
"events_url": "https://api.github.com/users/ajayvohra2005/events{/privacy}",
"followers_url": "https://api.github.com/users/ajayvohra2005/followers",
"following_url": "https://api.github.com/users/ajayvohra2005/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [] | 2025-01-07T21:03:30 | 2025-01-08T15:00:37 | 2025-01-08T14:35:52 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
Trying to download Hugging Face datasets using Hugging Face CLI raises error. This error only started after December 27th, 2024. For example:
```
huggingface-cli download --repo-type dataset gboleda/wikicorpus
Traceback (most recent call last):
File "/home/ubuntu/test_venv/bin/huggingface... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7362/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7361/comments | https://api.github.com/repos/huggingface/datasets/issues/7361/events | https://github.com/huggingface/datasets/pull/7361 | 2,771,859,244 | PR_kwDODunzps6G4t2p | 7,361 | Fix lock permission | {
"avatar_url": "https://avatars.githubusercontent.com/u/11530592?v=4",
"events_url": "https://api.github.com/users/cih9088/events{/privacy}",
"followers_url": "https://api.github.com/users/cih9088/followers",
"following_url": "https://api.github.com/users/cih9088/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [] | 2025-01-07T04:15:53 | 2025-01-07T04:49:46 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | All files except lock file have proper permission obeying `ACL` property if it is set.
If the cache directory has `ACL` property, it should be respected instead of just using `umask` for permission.
To fix it, just create a lock file and pass the created `mode`.
By creating a lock file with `touch()` before `Fil... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7361/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7361.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7361",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7361.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7361"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/7360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7360/comments | https://api.github.com/repos/huggingface/datasets/issues/7360/events | https://github.com/huggingface/datasets/issues/7360 | 2,771,751,406 | I_kwDODunzps6lNZHu | 7,360 | error when loading dataset in Hugging Face: NoneType error is not callable | {
"avatar_url": "https://avatars.githubusercontent.com/u/189343338?v=4",
"events_url": "https://api.github.com/users/nanu23333/events{/privacy}",
"followers_url": "https://api.github.com/users/nanu23333/followers",
"following_url": "https://api.github.com/users/nanu23333/following{/other_user}",
"gists_url": ... | [] | open | false | null | [] | null | [] | 2025-01-07T02:11:36 | 2025-01-10T10:44:38 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
I met an error when running a notebook provide by Hugging Face, and met the error.
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[2], line 5
3 # Load the enhancers dat... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7360/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7360/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7359/comments | https://api.github.com/repos/huggingface/datasets/issues/7359/events | https://github.com/huggingface/datasets/issues/7359 | 2,771,137,842 | I_kwDODunzps6lLDUy | 7,359 | There are multiple 'mteb/arguana' configurations in the cache: default, corpus, queries with HF_HUB_OFFLINE=1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/723146?v=4",
"events_url": "https://api.github.com/users/Bhavya6187/events{/privacy}",
"followers_url": "https://api.github.com/users/Bhavya6187/followers",
"following_url": "https://api.github.com/users/Bhavya6187/following{/other_user}",
"gists_url": ... | [] | open | false | null | [] | null | [] | 2025-01-06T17:42:49 | 2025-01-06T17:43:31 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
Hey folks,
I am trying to run this code -
```python
from datasets import load_dataset, get_dataset_config_names
ds = load_dataset("mteb/arguana")
```
with HF_HUB_OFFLINE=1
But I get the following error -
```python
Using the latest cached version of the dataset since mteb/arguana... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7359/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7359/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7358/comments | https://api.github.com/repos/huggingface/datasets/issues/7358/events | https://github.com/huggingface/datasets/pull/7358 | 2,770,927,769 | PR_kwDODunzps6G1kka | 7,358 | Fix remove_columns in the formatted case | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [] | 2025-01-06T15:44:23 | 2025-01-06T15:46:46 | 1970-01-01T00:00:00 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | `remove_columns` had no effect when running a function in `.map()` on dataset that is formatted
This aligns the logic of `map()` with the non formatted case and also with with https://github.com/huggingface/datasets/pull/7353 | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7358/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7358/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7358.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7358",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7358.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7358"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/7357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7357/comments | https://api.github.com/repos/huggingface/datasets/issues/7357/events | https://github.com/huggingface/datasets/issues/7357 | 2,770,456,127 | I_kwDODunzps6lIc4_ | 7,357 | Python process aborded with GIL issue when using image dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/25342812?v=4",
"events_url": "https://api.github.com/users/AlexKoff88/events{/privacy}",
"followers_url": "https://api.github.com/users/AlexKoff88/followers",
"following_url": "https://api.github.com/users/AlexKoff88/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [] | 2025-01-06T11:29:30 | 2025-01-09T14:00:46 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
The issue is visible only with the latest `datasets==3.2.0`.
When using image dataset the Python process gets aborted right before the exit with the following error:
```
Fatal Python error: PyGILState_Release: thread state 0x7fa1f409ade0 must be current when releasing
Python runtime state: f... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7357/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7357/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7356/comments | https://api.github.com/repos/huggingface/datasets/issues/7356/events | https://github.com/huggingface/datasets/issues/7356 | 2,770,095,103 | I_kwDODunzps6lHEv_ | 7,356 | How about adding a feature to pass the key when performing map on DatasetDict? | {
"avatar_url": "https://avatars.githubusercontent.com/u/93233241?v=4",
"events_url": "https://api.github.com/users/jp1924/events{/privacy}",
"followers_url": "https://api.github.com/users/jp1924/followers",
"following_url": "https://api.github.com/users/jp1924/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2025-01-06T08:13:52 | 2025-01-13T14:30:48 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Feature request
Add a feature to pass the key of the DatasetDict when performing map
### Motivation
I often preprocess using map on DatasetDict.
Sometimes, I need to preprocess train and valid data differently depending on the task.
So, I thought it would be nice to pass the key (like train, valid) when perf... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7356/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7356/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7355/comments | https://api.github.com/repos/huggingface/datasets/issues/7355/events | https://github.com/huggingface/datasets/issues/7355 | 2,768,958,211 | I_kwDODunzps6lCvMD | 7,355 | Not available datasets[audio] on python 3.13 | {
"avatar_url": "https://avatars.githubusercontent.com/u/70306948?v=4",
"events_url": "https://api.github.com/users/sergiosinlimites/events{/privacy}",
"followers_url": "https://api.github.com/users/sergiosinlimites/followers",
"following_url": "https://api.github.com/users/sergiosinlimites/following{/other_use... | [] | open | false | null | [] | null | [] | 2025-01-04T18:37:08 | 2025-01-10T10:46:00 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
This is the error I got, it seems numba package does not support python 3.13
PS C:\Users\sergi\Documents> pip install datasets[audio]
Defaulting to user installation because normal site-packages is not writeable
Collecting datasets[audio]
Using cached datasets-3.2.0-py3-none-any.whl.metada... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7355/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7355/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7354/comments | https://api.github.com/repos/huggingface/datasets/issues/7354/events | https://github.com/huggingface/datasets/issues/7354 | 2,768,955,917 | I_kwDODunzps6lCuoN | 7,354 | A module that was compiled using NumPy 1.x cannot be run in NumPy 2.0.2 as it may crash. To support both 1.x and 2.x versions of NumPy, modules must be compiled with NumPy 2.0. Some module may need to rebuild instead e.g. with 'pybind11>=2.12'. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1394644?v=4",
"events_url": "https://api.github.com/users/jamessdixon/events{/privacy}",
"followers_url": "https://api.github.com/users/jamessdixon/followers",
"following_url": "https://api.github.com/users/jamessdixon/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [] | 2025-01-04T18:30:17 | 2025-01-08T02:20:58 | 2025-01-08T02:20:58 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
Following this tutorial: https://huggingface.co/docs/diffusers/en/tutorials/basic_training and running it locally using VSCode on my MacBook. The first line in the tutorial fails: from datasets import load_dataset
dataset = load_dataset('huggan/smithsonian_butterflies_subset', split="train"). w... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1394644?v=4",
"events_url": "https://api.github.com/users/jamessdixon/events{/privacy}",
"followers_url": "https://api.github.com/users/jamessdixon/followers",
"following_url": "https://api.github.com/users/jamessdixon/following{/other_user}",
"gists_ur... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7354/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7353/comments | https://api.github.com/repos/huggingface/datasets/issues/7353/events | https://github.com/huggingface/datasets/pull/7353 | 2,768,484,726 | PR_kwDODunzps6Gtd6K | 7,353 | changes to MappedExamplesIterable to resolve #7345 | {
"avatar_url": "https://avatars.githubusercontent.com/u/12157034?v=4",
"events_url": "https://api.github.com/users/vttrifonov/events{/privacy}",
"followers_url": "https://api.github.com/users/vttrifonov/followers",
"following_url": "https://api.github.com/users/vttrifonov/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2025-01-04T06:01:15 | 2025-01-07T11:56:41 | 2025-01-07T11:56:41 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | modified `MappedExamplesIterable` and `test_iterable_dataset.py::test_mapped_examples_iterable_with_indices`
fix #7345
@lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7353/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7353.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7353",
"merged_at": "2025-01-07T11:56:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7353.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7352/comments | https://api.github.com/repos/huggingface/datasets/issues/7352/events | https://github.com/huggingface/datasets/pull/7352 | 2,767,763,850 | PR_kwDODunzps6GrBB5 | 7,352 | fsspec 2024.12.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2025-01-03T15:32:25 | 2025-01-03T15:34:54 | 2025-01-03T15:34:11 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7352/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7352.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7352",
"merged_at": "2025-01-03T15:34:11Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7352.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7350/comments | https://api.github.com/repos/huggingface/datasets/issues/7350/events | https://github.com/huggingface/datasets/pull/7350 | 2,767,731,707 | PR_kwDODunzps6Gq6Bf | 7,350 | Bump hfh to 0.24 to fix ci | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2025-01-03T15:09:40 | 2025-01-03T15:12:17 | 2025-01-03T15:10:27 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7350/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7350/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7350.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7350",
"merged_at": "2025-01-03T15:10:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7350.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7349/comments | https://api.github.com/repos/huggingface/datasets/issues/7349/events | https://github.com/huggingface/datasets/pull/7349 | 2,767,670,454 | PR_kwDODunzps6GqseO | 7,349 | Webdataset special columns in last position | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2025-01-03T14:32:15 | 2025-01-03T14:34:39 | 2025-01-03T14:32:30 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Place columns "__key__" and "__url__" in last position in the Dataset Viewer since they are not the main content
before:
<img width="1012" alt="image" src="https://github.com/user-attachments/assets/b556c1fe-2674-4ba0-9643-c074aa9716fd" />
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7349/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7349/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7349.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7349",
"merged_at": "2025-01-03T14:32:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7349.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7348/comments | https://api.github.com/repos/huggingface/datasets/issues/7348/events | https://github.com/huggingface/datasets/pull/7348 | 2,766,128,230 | PR_kwDODunzps6Gldcy | 7,348 | Catch OSError for arrow | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2025-01-02T14:30:00 | 2025-01-09T14:25:06 | 2025-01-09T14:25:04 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | fixes https://github.com/huggingface/datasets/issues/7346
(also updated `ruff` and appleid style changes) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7348/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7348.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7348",
"merged_at": "2025-01-09T14:25:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7348.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7347/comments | https://api.github.com/repos/huggingface/datasets/issues/7347/events | https://github.com/huggingface/datasets/issues/7347 | 2,760,282,339 | I_kwDODunzps6khpDj | 7,347 | Converting Arrow to WebDataset TAR Format for Offline Use | {
"avatar_url": "https://avatars.githubusercontent.com/u/91370128?v=4",
"events_url": "https://api.github.com/users/katie312/events{/privacy}",
"followers_url": "https://api.github.com/users/katie312/followers",
"following_url": "https://api.github.com/users/katie312/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 2024-12-27T01:40:44 | 2024-12-31T17:38:00 | 2024-12-28T15:38:03 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Feature request
Hi,
I've downloaded an Arrow-formatted dataset offline using the hugggingface's datasets library by:
```
import json
from datasets import load_dataset
dataset = load_dataset("pixparse/cc3m-wds")
dataset.save_to_disk("./cc3m_1")
```
now I need to convert it to WebDataset's TAR form... | {
"avatar_url": "https://avatars.githubusercontent.com/u/91370128?v=4",
"events_url": "https://api.github.com/users/katie312/events{/privacy}",
"followers_url": "https://api.github.com/users/katie312/followers",
"following_url": "https://api.github.com/users/katie312/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7347/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7347/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7346/comments | https://api.github.com/repos/huggingface/datasets/issues/7346/events | https://github.com/huggingface/datasets/issues/7346 | 2,758,752,118 | I_kwDODunzps6kbzd2 | 7,346 | OSError: Invalid flatbuffers message. | {
"avatar_url": "https://avatars.githubusercontent.com/u/46232487?v=4",
"events_url": "https://api.github.com/users/antecede/events{/privacy}",
"followers_url": "https://api.github.com/users/antecede/followers",
"following_url": "https://api.github.com/users/antecede/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2024-12-25T11:38:52 | 2025-01-09T14:25:29 | 2025-01-09T14:25:05 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
When loading a large 2D data (1000 × 1152) with a large number of (2,000 data in this case) in `load_dataset`, the error message `OSError: Invalid flatbuffers message` is reported.
When only 300 pieces of data of this size (1000 × 1152) are stored, they can be loaded correctly.
When 2,00... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7346/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7345/comments | https://api.github.com/repos/huggingface/datasets/issues/7345/events | https://github.com/huggingface/datasets/issues/7345 | 2,758,585,709 | I_kwDODunzps6kbK1t | 7,345 | Different behaviour of IterableDataset.map vs Dataset.map with remove_columns | {
"avatar_url": "https://avatars.githubusercontent.com/u/12157034?v=4",
"events_url": "https://api.github.com/users/vttrifonov/events{/privacy}",
"followers_url": "https://api.github.com/users/vttrifonov/followers",
"following_url": "https://api.github.com/users/vttrifonov/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2024-12-25T07:36:48 | 2025-01-07T11:56:42 | 2025-01-07T11:56:42 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
The following code
```python
import datasets as hf
ds1 = hf.Dataset.from_list([{'i': i} for i in [0,1]])
#ds1 = ds1.to_iterable_dataset()
ds2 = ds1.map(
lambda i: {'i': i+1},
input_columns = ['i'],
remove_columns = ['i']
)
list(ds2)
```
produces
```python
[{'i': ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7345/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7344/comments | https://api.github.com/repos/huggingface/datasets/issues/7344/events | https://github.com/huggingface/datasets/issues/7344 | 2,754,735,951 | I_kwDODunzps6kMe9P | 7,344 | HfHubHTTPError: 429 Client Error: Too Many Requests for URL when trying to access SlimPajama-627B or c4 on TPUs | {
"avatar_url": "https://avatars.githubusercontent.com/u/9397233?v=4",
"events_url": "https://api.github.com/users/clankur/events{/privacy}",
"followers_url": "https://api.github.com/users/clankur/followers",
"following_url": "https://api.github.com/users/clankur/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2024-12-22T16:30:07 | 2025-01-15T05:32:00 | 2025-01-15T05:31:58 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
I am trying to run some trainings on Google's TPUs using Huggingface's DataLoader on [SlimPajama-627B](https://huggingface.co/datasets/cerebras/SlimPajama-627B) and [c4](https://huggingface.co/datasets/allenai/c4), but I end up running into `429 Client Error: Too Many Requests for URL` error when ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9397233?v=4",
"events_url": "https://api.github.com/users/clankur/events{/privacy}",
"followers_url": "https://api.github.com/users/clankur/followers",
"following_url": "https://api.github.com/users/clankur/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7344/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7344/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7343/comments | https://api.github.com/repos/huggingface/datasets/issues/7343/events | https://github.com/huggingface/datasets/issues/7343 | 2,750,525,823 | I_kwDODunzps6j8bF_ | 7,343 | [Bug] Inconsistent behavior of data_files and data_dir in load_dataset method. | {
"avatar_url": "https://avatars.githubusercontent.com/u/74161960?v=4",
"events_url": "https://api.github.com/users/JasonCZH4/events{/privacy}",
"followers_url": "https://api.github.com/users/JasonCZH4/followers",
"following_url": "https://api.github.com/users/JasonCZH4/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2024-12-19T14:31:27 | 2025-01-03T15:54:09 | 2025-01-03T15:54:09 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
Inconsistent operation of data_files and data_dir in load_dataset method.
### Steps to reproduce the bug
# First
I have three files, named 'train.json', 'val.json', 'test.json'.
Each one has a simple dict `{text:'aaa'}`.
Their path are `/data/train.json`, `/data/val.json`, `/data/test.jso... | {
"avatar_url": "https://avatars.githubusercontent.com/u/74161960?v=4",
"events_url": "https://api.github.com/users/JasonCZH4/events{/privacy}",
"followers_url": "https://api.github.com/users/JasonCZH4/followers",
"following_url": "https://api.github.com/users/JasonCZH4/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7343/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7343/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7342/comments | https://api.github.com/repos/huggingface/datasets/issues/7342/events | https://github.com/huggingface/datasets/pull/7342 | 2,749,572,310 | PR_kwDODunzps6FvgcK | 7,342 | Update LICENSE | {
"avatar_url": "https://avatars.githubusercontent.com/u/97572401?v=4",
"events_url": "https://api.github.com/users/eliebak/events{/privacy}",
"followers_url": "https://api.github.com/users/eliebak/followers",
"following_url": "https://api.github.com/users/eliebak/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2024-12-19T08:17:50 | 2024-12-19T08:44:08 | 2024-12-19T08:44:08 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/97572401?v=4",
"events_url": "https://api.github.com/users/eliebak/events{/privacy}",
"followers_url": "https://api.github.com/users/eliebak/followers",
"following_url": "https://api.github.com/users/eliebak/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7342/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7342.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7342",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/7342.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7342"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/7341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7341/comments | https://api.github.com/repos/huggingface/datasets/issues/7341/events | https://github.com/huggingface/datasets/pull/7341 | 2,745,658,561 | PR_kwDODunzps6FiGlt | 7,341 | minor video docs on how to install | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2024-12-17T18:06:17 | 2024-12-17T18:11:17 | 2024-12-17T18:11:15 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7341/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7341/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7341.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7341",
"merged_at": "2024-12-17T18:11:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7341.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7340 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7340/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7340/comments | https://api.github.com/repos/huggingface/datasets/issues/7340/events | https://github.com/huggingface/datasets/pull/7340 | 2,745,473,274 | PR_kwDODunzps6FhdR2 | 7,340 | don't import soundfile in tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2024-12-17T16:49:55 | 2024-12-17T16:54:04 | 2024-12-17T16:50:24 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7340/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7340/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7340.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7340",
"merged_at": "2024-12-17T16:50:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7340.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7339 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7339/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7339/comments | https://api.github.com/repos/huggingface/datasets/issues/7339/events | https://github.com/huggingface/datasets/pull/7339 | 2,745,460,060 | PR_kwDODunzps6FhaTl | 7,339 | Update CONTRIBUTING.md | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2024-12-17T16:45:25 | 2024-12-17T16:51:36 | 2024-12-17T16:46:30 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7339/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7339/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7339.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7339",
"merged_at": "2024-12-17T16:46:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7339.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/... | true |
https://api.github.com/repos/huggingface/datasets/issues/7337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7337/comments | https://api.github.com/repos/huggingface/datasets/issues/7337/events | https://github.com/huggingface/datasets/issues/7337 | 2,744,877,569 | I_kwDODunzps6jm4IB | 7,337 | One or several metadata.jsonl were found, but not in the same directory or in a parent directory of | {
"avatar_url": "https://avatars.githubusercontent.com/u/67250532?v=4",
"events_url": "https://api.github.com/users/mst272/events{/privacy}",
"followers_url": "https://api.github.com/users/mst272/followers",
"following_url": "https://api.github.com/users/mst272/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [] | 2024-12-17T12:58:43 | 2025-01-03T15:28:13 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
ImageFolder with metadata.jsonl error. I downloaded liuhaotian/LLaVA-CC3M-Pretrain-595K locally from Hugging Face. According to the tutorial in https://huggingface.co/docs/datasets/image_dataset#image-captioning, only put images.zip and metadata.jsonl containing information in the same folder. How... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7337/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7336 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7336/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7336/comments | https://api.github.com/repos/huggingface/datasets/issues/7336/events | https://github.com/huggingface/datasets/issues/7336 | 2,744,746,456 | I_kwDODunzps6jmYHY | 7,336 | Clarify documentation or Create DatasetCard | {
"avatar_url": "https://avatars.githubusercontent.com/u/145011209?v=4",
"events_url": "https://api.github.com/users/August-murr/events{/privacy}",
"followers_url": "https://api.github.com/users/August-murr/followers",
"following_url": "https://api.github.com/users/August-murr/following{/other_user}",
"gists_... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2024-12-17T12:01:00 | 2024-12-17T12:01:00 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Feature request
I noticed that you can use a Model Card instead of a Dataset Card when pushing a dataset to the Hub, but this isn’t clearly mentioned in [the docs.](https://huggingface.co/docs/datasets/dataset_card)
- Update the docs to clarify that a Model Card can work for datasets too.
- It might be worth c... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7336/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7336/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7335 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7335/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7335/comments | https://api.github.com/repos/huggingface/datasets/issues/7335/events | https://github.com/huggingface/datasets/issues/7335 | 2,743,437,260 | I_kwDODunzps6jhYfM | 7,335 | Too many open files: '/root/.cache/huggingface/token' | {
"avatar_url": "https://avatars.githubusercontent.com/u/17604849?v=4",
"events_url": "https://api.github.com/users/kopyl/events{/privacy}",
"followers_url": "https://api.github.com/users/kopyl/followers",
"following_url": "https://api.github.com/users/kopyl/following{/other_user}",
"gists_url": "https://api.... | [] | open | false | null | [] | null | [] | 2024-12-16T21:30:24 | 2024-12-16T21:30:24 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
I ran this code:
```
from datasets import load_dataset
dataset = load_dataset("common-canvas/commoncatalog-cc-by", cache_dir="/datadrive/datasets/cc", num_proc=1000)
```
And got this error.
Before it was some other file though (lie something...incomplete)
runnting
```
ulimit -n 8192
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7335/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7335/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/7334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7334/comments | https://api.github.com/repos/huggingface/datasets/issues/7334/events | https://github.com/huggingface/datasets/issues/7334 | 2,740,266,503 | I_kwDODunzps6jVSYH | 7,334 | TypeError: Value.__init__() missing 1 required positional argument: 'dtype' | {
"avatar_url": "https://avatars.githubusercontent.com/u/185799756?v=4",
"events_url": "https://api.github.com/users/kakamond/events{/privacy}",
"followers_url": "https://api.github.com/users/kakamond/followers",
"following_url": "https://api.github.com/users/kakamond/following{/other_user}",
"gists_url": "ht... | [] | open | false | null | [] | null | [] | 2024-12-15T04:08:46 | 2024-12-15T04:08:46 | 1970-01-01T00:00:00 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ### Describe the bug
ds = load_dataset(
"./xxx.py",
name="default",
split="train",
)
The datasets does not support debugging locally anymore...
### Steps to reproduce the bug
```
from datasets import load_dataset
ds = load_dataset(
"./repo.py",
name="default",
split="train",
)
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7334/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7334/timeline | null | null | null | null | false |
GitHub Issues is a dataset consisting of GitHub issues and pull requests associated with the 🤗 Datasets repository. It is intended for educational purposes and can be used for semantic search or multilabel text classification. The contents of each GitHub issue are in English and concern the domain of datasets for NLP, computer vision, and beyond.
For each of the tasks tagged for this dataset, give a brief description of the tag, metrics, and suggested models (with a link to their HuggingFace implementation if available). Give a similar description of tasks that were not covered by the structured tag set (repace the task-category-tag with an appropriate other:other-task-name).
task-category-tag: The dataset can be used to train a model for [TASK NAME], which consists in [TASK DESCRIPTION]. Success on this task is typically measured by achieving a high/low metric name. The (model name or model class) model currently achieves the following score. [IF A LEADERBOARD IS AVAILABLE]: This task has an active leaderboard which can be found at leaderboard url and ranks models based on metric name while also reporting other metric name.Provide a brief overview of the languages represented in the dataset. Describe relevant details about specifics of the language such as whether it is social media text, African American English,...
When relevant, please provide BCP-47 codes, which consist of a primary language subtag, with a script subtag and/or region subtag if available.
Provide an JSON-formatted example and brief description of a typical instance in the dataset. If available, provide a link to further examples.
{
'example_field': ...,
...
}
Provide any additional information that is not covered in the other sections about the data here. In particular describe any relationships between data points and if these relationships are made explicit.
List and describe the fields present in the dataset. Mention their data type, and whether they are used as input or output in any of the tasks the dataset currently supports. If the data has span indices, describe their attributes, such as whether they are at the character level or word level, whether they are contiguous or not, etc. If the datasets contains example IDs, state whether they have an inherent meaning, such as a mapping to other datasets or pointing to relationships between data points.
example_field: description of example_fieldNote that the descriptions can be initialized with the Show Markdown Data Fields output of the tagging app, you will then only need to refine the generated descriptions.
Describe and name the splits in the dataset if there are more than one.
Describe any criteria for splitting the data, if used. If their are differences between the splits (e.g. if the training annotations are machine-generated and the dev and test ones are created by humans, or if different numbers of annotators contributed to each example), describe them here.
Provide the sizes of each split. As appropriate, provide any descriptive statistics for the features, such as average length. For example:
| Tain | Valid | Test | |
|---|---|---|---|
| Input Sentences | |||
| Average Sentence Length |
What need motivated the creation of this dataset? What are some of the reasons underlying the major choices involved in putting it together?
This section describes the source data (e.g. news text and headlines, social media posts, translated sentences,...)
Describe the data collection process. Describe any criteria for data selection or filtering. List any key words or search terms used. If possible, include runtime information for the collection process.
If data was collected from other pre-existing datasets, link to source here and to their Hugging Face version.
If the data was modified or normalized after being collected (e.g. if the data is word-tokenized), describe the process and the tools used.
State whether the data was produced by humans or machine generated. Describe the people or systems who originally created the data.
If available, include self-reported demographic or identity information for the source data creators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was created (for example, if the producers were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
Describe other people represented or mentioned in the data. Where possible, link to references for the information.
If the dataset contains annotations which are not part of the initial data collection, describe them in the following paragraphs.
If applicable, describe the annotation process and any tools used, or state otherwise. Describe the amount of data annotated, if not all. Describe or reference annotation guidelines provided to the annotators. If available, provide interannotator statistics. Describe any annotation validation processes.
If annotations were collected for the source data (such as class labels or syntactic parses), state whether the annotations were produced by humans or machine generated.
Describe the people or systems who originally created the annotations and their selection criteria if applicable.
If available, include self-reported demographic or identity information for the annotators, but avoid inferring this information. Instead state that this information is unknown. See Larson 2017 for using identity categories as a variables, particularly gender.
Describe the conditions under which the data was annotated (for example, if the annotators were crowdworkers, state what platform was used, or if the data was found, what website the data was found on). If compensation was provided, include that information here.
State whether the dataset uses identity categories and, if so, how the information is used. Describe where this information comes from (i.e. self-reporting, collecting from profiles, inferring, etc.). See Larson 2017 for using identity categories as a variables, particularly gender. State whether the data is linked to individuals and whether those individuals can be identified in the dataset, either directly or indirectly (i.e., in combination with other data).
State whether the dataset contains other data that might be considered sensitive (e.g., data that reveals racial or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history).
If efforts were made to anonymize the data, describe the anonymization process.
Please discuss some of the ways you believe the use of this dataset will impact society.
The statement should include both positive outlooks, such as outlining how technologies developed through its use may improve people's lives, and discuss the accompanying risks. These risks may range from making important decisions more opaque to people who are affected by the technology, to reinforcing existing harmful biases (whose specifics should be discussed in the next section), among other considerations.
Also describe in this section if the proposed dataset contains a low-resource or under-represented language. If this is the case or if this task has any impact on underserved communities, please elaborate here.
Provide descriptions of specific biases that are likely to be reflected in the data, and state whether any steps were taken to reduce their impact.
For Wikipedia text, see for example Dinan et al 2020 on biases in Wikipedia (esp. Table 1), or Blodgett et al 2020 for a more general discussion of the topic.
If analyses have been run quantifying these biases, please add brief summaries and links to the studies here.
If studies of the datasets have outlined other limitations of the dataset, such as annotation artifacts, please outline and cite them here.
List the people involved in collecting the dataset and their affiliation(s). If funding information is known, include it here.
Provide the license and link to the license webpage if available.
Provide the BibTex-formatted reference for the dataset. For example:
@article{article_id,
author = {Author List},
title = {Dataset Paper Title},
journal = {Publication Venue},
year = {2525}
}
If the dataset has a DOI, please provide it here.