
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.32B | node_id stringlengths 18 32 | number int64 1 4.75k | title stringlengths 1 276 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees list | milestone null | comments sequence | created_at int64 1,587B 1,659B | updated_at int64 1,587B 1,659B | closed_at null 1,587B 1,659B ⌀ | author_association stringclasses 3
values | active_lock_reason null | draft bool 2
classes | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason nullclasses 3
values | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4748/comments | https://api.github.com/repos/huggingface/datasets/issues/4748/events | https://github.com/huggingface/datasets/pull/4748 | 1,318,874,913 | PR_kwDODunzps48JTEb | 4,748 | Add image classification processing guide | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4748). All of your documentation changes will be reflected on that endpoint."
] | 1,658,880,671,000 | 1,658,881,072,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4748",
"html_url": "https://github.com/huggingface/datasets/pull/4748",
"diff_url": "https://github.com/huggingface/datasets/pull/4748.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4748.patch",
"merged_at": null
} | This PR follows up on #4710 to separate the object detection and image classification guides. It expands a little more on the original guide to include a more complete example of loading and transforming a whole dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4748/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4748/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4747/comments | https://api.github.com/repos/huggingface/datasets/issues/4747/events | https://github.com/huggingface/datasets/pull/4747 | 1,318,586,932 | PR_kwDODunzps48IWKj | 4,747 | Shard parquet in `download_and_prepare` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4747). All of your documentation changes will be reflected on that endpoint."
] | 1,658,858,701,000 | 1,658,859,098,000 | null | MEMBER | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4747",
"html_url": "https://github.com/huggingface/datasets/pull/4747",
"diff_url": "https://github.com/huggingface/datasets/pull/4747.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4747.patch",
"merged_at": null
} | Following https://github.com/huggingface/datasets/pull/4724 (needs to be merged first)
It's good practice to shard parquet files to enable parallelism with spark/dask/etc.
I added the `max_shard_size` parameter to `download_and_prepare` (default to 500MB for parquet, and None for arrow).
```python
from datase... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4747/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4746/comments | https://api.github.com/repos/huggingface/datasets/issues/4746/events | https://github.com/huggingface/datasets/issues/4746 | 1,318,486,599 | I_kwDODunzps5OloJH | 4,746 | Dataset Viewer issue for yanekyuk/wikikey | {
"login": "ai-ashok",
"id": 91247690,
"node_id": "MDQ6VXNlcjkxMjQ3Njkw",
"avatar_url": "https://avatars.githubusercontent.com/u/91247690?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ai-ashok",
"html_url": "https://github.com/ai-ashok",
"followers_url": "https://api.github.com/users/ai-... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"The dataset is empty, as far as I can tell: there are no files in the repository at https://huggingface.co/datasets/yanekyuk/wikikey/tree/main\r\n\r\nMaybe the viewer can display a better message for empty datasets"
] | 1,658,852,716,000 | 1,658,858,857,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4746/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4745/comments | https://api.github.com/repos/huggingface/datasets/issues/4745/events | https://github.com/huggingface/datasets/issues/4745 | 1,318,016,655 | I_kwDODunzps5Oj1aP | 4,745 | Allow `list_datasets` to include private datasets | {
"login": "ola13",
"id": 1528523,
"node_id": "MDQ6VXNlcjE1Mjg1MjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1528523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ola13",
"html_url": "https://github.com/ola13",
"followers_url": "https://api.github.com/users/ola13/follower... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Thanks for opening this issue :)\r\n\r\nIf it can help, I think you can already use `huggingface_hub` to achieve this:\r\n```python\r\n>>> from huggingface_hub import HfApi\r\n>>> [ds_info.id for ds_info in HfApi().list_datasets(use_auth_token=token) if ds_info.private]\r\n['bigscience/xxxx', 'bigscience-catalogue... | 1,658,830,568,000 | 1,658,836,765,000 | null | NONE | null | null | null | I am working with a large collection of private datasets, it would be convenient for me to be able to list them.
I would envision extending the convention of using `use_auth_token` keyword argument to `list_datasets` function, then calling:
```
list_datasets(use_auth_token="my_token")
```
would return the li... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4745/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4744/comments | https://api.github.com/repos/huggingface/datasets/issues/4744/events | https://github.com/huggingface/datasets/issues/4744 | 1,317,822,345 | I_kwDODunzps5OjF-J | 4,744 | Remove instructions to generate dummy data from our docs | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Note that for me personally, conceptually all the dummy data (even for \"canonical\" datasets) should be superseded by `datasets-server`, which performs some kind of CI/CD of datasets (including the canonical ones)",
"I totally agree: next step should be rethinking if dummy data makes sense for canonical dataset... | 1,658,820,778,000 | 1,658,823,453,000 | null | MEMBER | null | null | null | In our docs, we indicate to generate the dummy data: https://huggingface.co/docs/datasets/dataset_script#testing-data-and-checksum-metadata
However:
- dummy data makes sense only for datasets in our GitHub repo: so that we can test their loading with our CI
- for datasets on the Hub:
- they do not pass any CI t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4744/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4744/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4743/comments | https://api.github.com/repos/huggingface/datasets/issues/4743/events | https://github.com/huggingface/datasets/pull/4743 | 1,317,362,561 | PR_kwDODunzps48EUFs | 4,743 | Update map docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4743). All of your documentation changes will be reflected on that endpoint."
] | 1,658,782,775,000 | 1,658,783,163,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4743",
"html_url": "https://github.com/huggingface/datasets/pull/4743",
"diff_url": "https://github.com/huggingface/datasets/pull/4743.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4743.patch",
"merged_at": null
} | This PR updates the `map` docs for processing text to include `return_tensors="np"` to make it run faster (see #4676). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4743/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4742/comments | https://api.github.com/repos/huggingface/datasets/issues/4742/events | https://github.com/huggingface/datasets/issues/4742 | 1,317,260,663 | I_kwDODunzps5Og813 | 4,742 | Dummy data nowhere to be found | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi @BramVanroy, thanks for reporting.\r\n\r\nFirst of all, please note that you do not need the dummy data: this was the case when we were adding datasets to the `datasets` library (on this GitHub repo), so that we could test the correct loading of all datasets with our CI. However, this is no longer the case for ... | 1,658,776,722,000 | 1,658,820,827,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
To finalize my dataset, I wanted to create dummy data as per the guide and I ran
```shell
datasets-cli dummy_data datasets/hebban-reviews --auto_generate
```
where hebban-reviews is [this repo](https://huggingface.co/datasets/BramVanroy/hebban-reviews). And even though the scripts runs an... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4742/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4741/comments | https://api.github.com/repos/huggingface/datasets/issues/4741/events | https://github.com/huggingface/datasets/pull/4741 | 1,316,621,272 | PR_kwDODunzps48B2fl | 4,741 | Fix to dict conversion of `DatasetInfo`/`Features` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,745,687,000 | 1,658,753,436,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4741",
"html_url": "https://github.com/huggingface/datasets/pull/4741",
"diff_url": "https://github.com/huggingface/datasets/pull/4741.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4741.patch",
"merged_at": 1658752673000
} | Fix #4681 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4740/comments | https://api.github.com/repos/huggingface/datasets/issues/4740/events | https://github.com/huggingface/datasets/pull/4740 | 1,316,478,007 | PR_kwDODunzps48BX5l | 4,740 | Fix multiprocessing in map_nested | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4740). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq as a workaround to preserve previous behavior, the parameter `multiprocessing_min_length=16` is passed from `download` to `map_nested`, so... | 1,658,738,659,000 | 1,658,860,880,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4740",
"html_url": "https://github.com/huggingface/datasets/pull/4740",
"diff_url": "https://github.com/huggingface/datasets/pull/4740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4740.patch",
"merged_at": null
} | As previously discussed:
Before, multiprocessing was not used in `map_nested` if `num_proc` was greater than or equal to `len(iterable)`.
- Multiprocessing was not used e.g. when passing `num_proc=20` but having 19 files to download
- As by default, `DownloadManager` sets `num_proc=16`, before multiprocessing was ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4740/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4739/comments | https://api.github.com/repos/huggingface/datasets/issues/4739/events | https://github.com/huggingface/datasets/pull/4739 | 1,316,400,915 | PR_kwDODunzps48BHdE | 4,739 | Deprecate metrics | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4739). All of your documentation changes will be reflected on that endpoint.",
"I mark this as Draft because the deprecated version number needs being updated after the latest release.",
"Perhaps now is the time to also updat... | 1,658,734,555,000 | 1,658,869,190,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4739",
"html_url": "https://github.com/huggingface/datasets/pull/4739",
"diff_url": "https://github.com/huggingface/datasets/pull/4739.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4739.patch",
"merged_at": null
} | Deprecate metrics:
- deprecate public functions: `load_metric`, `list_metrics` and `inspect_metric`: docstring and warning
- test deprecation warnings are issues
- deprecate metrics in all docs
- remove mentions to metrics in docs and README
- deprecate internal functions/classes
Maybe we should also stop testi... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4739/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4739/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4738/comments | https://api.github.com/repos/huggingface/datasets/issues/4738/events | https://github.com/huggingface/datasets/pull/4738 | 1,315,222,166 | PR_kwDODunzps479hq4 | 4,738 | Use CI unit/integration tests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think this PR can be merged. Willing to see it in action.\r\n\r\nCC: @lhoestq "
] | 1,658,508,480,000 | 1,658,866,762,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4738",
"html_url": "https://github.com/huggingface/datasets/pull/4738",
"diff_url": "https://github.com/huggingface/datasets/pull/4738.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4738.patch",
"merged_at": 1658866025000
} | This PR:
- Implements separate unit/integration tests
- A fail in integration tests does not cancel the rest of the jobs
- We should implement more robust integration tests: work in progress in a subsequent PR
- For the moment, test involving network requests are marked as integration: to be evolved | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4738/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4738/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4737/comments | https://api.github.com/repos/huggingface/datasets/issues/4737/events | https://github.com/huggingface/datasets/issues/4737 | 1,315,011,004 | I_kwDODunzps5OYXm8 | 4,737 | Download error on scene_parse_150 | {
"login": "juliensimon",
"id": 3436143,
"node_id": "MDQ6VXNlcjM0MzYxNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/juliensimon",
"html_url": "https://github.com/juliensimon",
"followers_url": "https://api.github.com/us... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi! The server with the data seems to be down. I've reported this issue (https://github.com/CSAILVision/sceneparsing/issues/34) in the dataset repo. "
] | 1,658,496,508,000 | 1,658,500,151,000 | null | NONE | null | null | null | ```
from datasets import load_dataset
dataset = load_dataset("scene_parse_150", "scene_parsing")
FileNotFoundError: Couldn't find file at http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4737/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4736/comments | https://api.github.com/repos/huggingface/datasets/issues/4736/events | https://github.com/huggingface/datasets/issues/4736 | 1,314,931,996 | I_kwDODunzps5OYEUc | 4,736 | Dataset Viewer issue for deepklarity/huggingface-spaces-dataset | {
"login": "dk-crazydiv",
"id": 47515542,
"node_id": "MDQ6VXNlcjQ3NTE1NTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47515542?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dk-crazydiv",
"html_url": "https://github.com/dk-crazydiv",
"followers_url": "https://api.github.com/... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Thanks for reporting. You're right, workers were under-provisioned due to a manual error, and the job queue was full. It's fixed now."
] | 1,658,492,058,000 | 1,658,497,598,000 | null | NONE | null | null | null | ### Link
https://huggingface.co/datasets/deepklarity/huggingface-spaces-dataset/viewer/deepklarity--huggingface-spaces-dataset/train
### Description
Hi Team,
I'm getting the following error on a uploaded dataset. I'm getting the same status for a couple of hours now. The dataset size is `<1MB` and the format is cs... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4736/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4735/comments | https://api.github.com/repos/huggingface/datasets/issues/4735/events | https://github.com/huggingface/datasets/pull/4735 | 1,314,501,641 | PR_kwDODunzps477CuP | 4,735 | Pin rouge_score test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,474,301,000 | 1,658,476,694,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4735",
"html_url": "https://github.com/huggingface/datasets/pull/4735",
"diff_url": "https://github.com/huggingface/datasets/pull/4735.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4735.patch",
"merged_at": 1658475918000
} | Temporarily pin `rouge_score` (to avoid latest version 0.7.0) until the issue is fixed.
Fix #4734 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4735/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4735/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4734/comments | https://api.github.com/repos/huggingface/datasets/issues/4734/events | https://github.com/huggingface/datasets/issues/4734 | 1,314,495,382 | I_kwDODunzps5OWZuW | 4,734 | Package rouge-score cannot be imported | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"We have added a comment on an existing issue opened in their repo: https://github.com/google-research/google-research/issues/1212#issuecomment-1192267130\r\n- https://github.com/google-research/google-research/issues/1212"
] | 1,658,474,105,000 | 1,658,475,919,000 | null | MEMBER | null | null | null | ## Describe the bug
After the today release of `rouge_score-0.0.7` it seems no longer importable. Our CI fails: https://github.com/huggingface/datasets/runs/7463218591?check_suite_focus=true
```
FAILED tests/test_dataset_common.py::LocalDatasetTest::test_builder_class_bigbench
FAILED tests/test_dataset_common.py::L... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4734/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4733/comments | https://api.github.com/repos/huggingface/datasets/issues/4733/events | https://github.com/huggingface/datasets/issues/4733 | 1,314,479,616 | I_kwDODunzps5OWV4A | 4,733 | rouge metric | {
"login": "asking28",
"id": 29248466,
"node_id": "MDQ6VXNlcjI5MjQ4NDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/29248466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asking28",
"html_url": "https://github.com/asking28",
"followers_url": "https://api.github.com/users/ask... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Fixed by:\r\n- #4735"
] | 1,658,473,611,000 | 1,658,480,882,000 | null | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Loading Rouge metric gives error after latest rouge-score==0.0.7 release.
Downgrading rougemetric==0.0.4 works fine.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
## Expected results
A clear and concis... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4733/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4732/comments | https://api.github.com/repos/huggingface/datasets/issues/4732/events | https://github.com/huggingface/datasets/issues/4732 | 1,314,371,566 | I_kwDODunzps5OV7fu | 4,732 | Document better that loading a dataset passing its name does not use the local script | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Thanks for the feedback!\r\n\r\nI think since this issue is closely related to loading, I can add a clearer explanation under [Load > local loading script](https://huggingface.co/docs/datasets/main/en/loading#local-loading-script).",
"That makes sense but I think having a line about it under https://huggingface.... | 1,658,470,051,000 | 1,658,777,132,000 | null | MEMBER | null | null | null | As reported by @TrentBrick here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191858596, it could be more clear that loading a dataset by passing its name does not use the (modified) local script of it.
What he did:
- he installed `datasets` from source
- he modified locally `datasets/the_pile/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4732/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4732/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4731/comments | https://api.github.com/repos/huggingface/datasets/issues/4731/events | https://github.com/huggingface/datasets/pull/4731 | 1,313,773,348 | PR_kwDODunzps474dlZ | 4,731 | docs: ✏️ fix TranslationVariableLanguages example | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,435,741,000 | 1,658,473,260,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4731",
"html_url": "https://github.com/huggingface/datasets/pull/4731",
"diff_url": "https://github.com/huggingface/datasets/pull/4731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4731.patch",
"merged_at": 1658472522000
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4730/comments | https://api.github.com/repos/huggingface/datasets/issues/4730/events | https://github.com/huggingface/datasets/issues/4730 | 1,313,421,263 | I_kwDODunzps5OSTfP | 4,730 | Loading imagenet-1k validation split takes much more RAM than expected | {
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"My bad, `482 * 418 * 50000 * 3 / 1000000 = 30221 MB` ( https://stackoverflow.com/a/42979315 ).\r\n\r\nMeanwhile `256 * 256 * 50000 * 3 / 1000000 = 9830 MB`. We are loading the non-cropped images and that is why we take so much RAM."
] | 1,658,416,446,000 | 1,658,421,664,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading into memory the validation split of imagenet-1k takes much more RAM than expected. Assuming ImageNet-1k is 150 GB, split is 50000 validation images and 1,281,167 train images, I would expect only about 6 GB loaded in RAM.
## Steps to reproduce the bug
```python
from datasets import... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4730/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4729/comments | https://api.github.com/repos/huggingface/datasets/issues/4729/events | https://github.com/huggingface/datasets/pull/4729 | 1,313,374,015 | PR_kwDODunzps473GmR | 4,729 | Refactor Hub tests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,414,593,000 | 1,658,502,589,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4729",
"html_url": "https://github.com/huggingface/datasets/pull/4729",
"diff_url": "https://github.com/huggingface/datasets/pull/4729.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4729.patch",
"merged_at": 1658501789000
} | This PR refactors `test_upstream_hub` by removing unittests and using the following pytest Hub fixtures:
- `ci_hub_config`
- `set_ci_hub_access_token`: to replace setUp/tearDown
- `temporary_repo` context manager: to replace `try... finally`
- `cleanup_repo`: to delete repo accidentally created if one of the tests ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4729/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4728/comments | https://api.github.com/repos/huggingface/datasets/issues/4728/events | https://github.com/huggingface/datasets/issues/4728 | 1,312,897,454 | I_kwDODunzps5OQTmu | 4,728 | load_dataset gives "403" error when using Financial Phrasebank | {
"login": "rohitvincent",
"id": 2209134,
"node_id": "MDQ6VXNlcjIyMDkxMzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2209134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rohitvincent",
"html_url": "https://github.com/rohitvincent",
"followers_url": "https://api.github.com... | [] | open | false | null | [] | null | [
"Hi @rohitvincent, thanks for reporting.\r\n\r\nUnfortunately I'm not able to reproduce your issue:\r\n```python\r\nIn [2]: from datasets import load_dataset, DownloadMode\r\n ...: load_dataset(path='financial_phrasebank',name='sentences_allagree', download_mode=\"force_redownload\")\r\nDownloading builder script... | 1,658,393,012,000 | 1,658,478,333,000 | null | NONE | null | null | null | I tried both codes below to download the financial phrasebank dataset (https://huggingface.co/datasets/financial_phrasebank) with the sentences_allagree subset. However, the code gives a 403 error when executed from multiple machines locally or on the cloud.
```
from datasets import load_dataset, DownloadMode
load... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4728/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n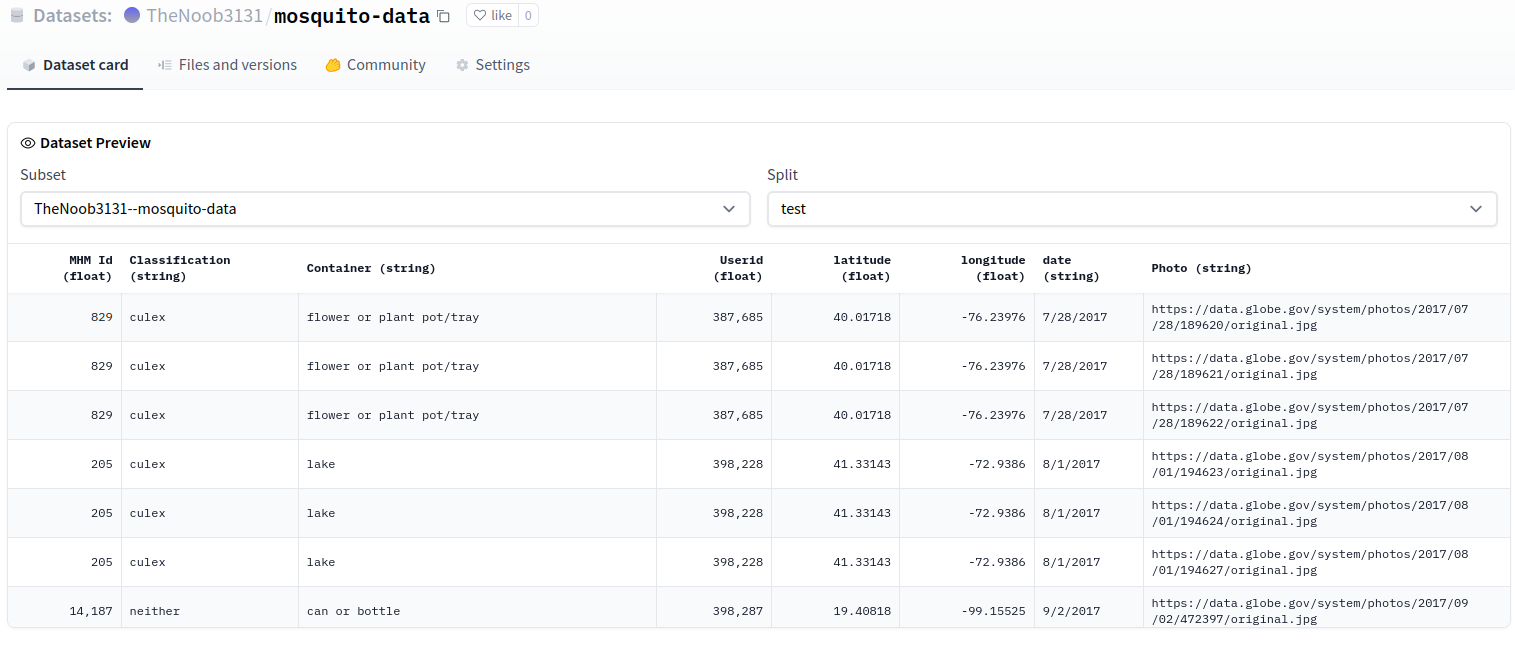\r\n\r\n"
] | 1,658,381,088,000 | 1,658,389,916,000 | null | NONE | null | null | null | ### Link
https://huggingface.co/datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4726/comments | https://api.github.com/repos/huggingface/datasets/issues/4726/events | https://github.com/huggingface/datasets/pull/4726 | 1,312,082,175 | PR_kwDODunzps47ykPI | 4,726 | Fix broken link to the Hub | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,357,847,000 | 1,658,413,998,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4726",
"html_url": "https://github.com/huggingface/datasets/pull/4726",
"diff_url": "https://github.com/huggingface/datasets/pull/4726.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4726.patch",
"merged_at": 1658390454000
} | The Markdown link fails to render if it is in the same line as the `<span>`. This PR implements @mishig25's fix by using `<a href=" ">` instead.
 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4726/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4725/comments | https://api.github.com/repos/huggingface/datasets/issues/4725/events | https://github.com/huggingface/datasets/issues/4725 | 1,311,907,096 | I_kwDODunzps5OMh0Y | 4,725 | the_pile datasets URL broken. | {
"login": "TrentBrick",
"id": 12433427,
"node_id": "MDQ6VXNlcjEyNDMzNDI3",
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TrentBrick",
"html_url": "https://github.com/TrentBrick",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @TrentBrick. We are addressing the change with their data host server.\r\n\r\nOn the meantime, if you would like to work with your fixed local copy of the_pile script, you should use:\r\n```python\r\nload_dataset(\"path/to/your/local/the_pile/the_pile.py\",...\r\n```\r\ninstead of just `load_... | 1,658,350,650,000 | 1,658,470,186,000 | null | NONE | null | null | null | https://github.com/huggingface/datasets/pull/3627 changed the Eleuther AI Pile dataset URL from https://the-eye.eu/ to https://mystic.the-eye.eu/ but the latter is now broken and the former works again.
Note that when I git clone the repo and use `pip install -e .` and then edit the URL back the codebase doesn't se... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4725/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4724/comments | https://api.github.com/repos/huggingface/datasets/issues/4724/events | https://github.com/huggingface/datasets/pull/4724 | 1,311,127,404 | PR_kwDODunzps47vLrP | 4,724 | Download and prepare as Parquet for cloud storage | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4724). All of your documentation changes will be reflected on that endpoint."
] | 1,658,324,342,000 | 1,658,769,419,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4724",
"html_url": "https://github.com/huggingface/datasets/pull/4724",
"diff_url": "https://github.com/huggingface/datasets/pull/4724.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4724.patch",
"merged_at": null
} | Download a dataset as Parquet in a cloud storage can be useful for streaming mode and to use with spark/dask/ray.
This PR adds support for `fsspec` URIs like `s3://...`, `gcs://...` etc. and ads the `file_format` to save as parquet instead of arrow:
```python
from datasets import *
cache_dir = "s3://..."
build... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4724/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4723 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4723/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4723/comments | https://api.github.com/repos/huggingface/datasets/issues/4723/events | https://github.com/huggingface/datasets/pull/4723 | 1,310,970,604 | PR_kwDODunzps47uoSj | 4,723 | Refactor conftest fixtures | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,319,322,000 | 1,658,414,231,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4723",
"html_url": "https://github.com/huggingface/datasets/pull/4723",
"diff_url": "https://github.com/huggingface/datasets/pull/4723.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4723.patch",
"merged_at": 1658413458000
} | Previously, fixture modules `hub_fixtures` and `s3_fixtures`:
- were both at the root test directory
- were imported using `import *`
- as a side effect, the modules `os` and `pytest` were imported from `s3_fixtures` into `conftest`
This PR:
- puts both fixture modules in a dedicated directory `fixtures`
- re... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4723/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4723/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4722/comments | https://api.github.com/repos/huggingface/datasets/issues/4722/events | https://github.com/huggingface/datasets/pull/4722 | 1,310,785,916 | PR_kwDODunzps47t_HJ | 4,722 | Docs: Fix same-page haslinks | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mis... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,311,477,000 | 1,658,336,553,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4722",
"html_url": "https://github.com/huggingface/datasets/pull/4722",
"diff_url": "https://github.com/huggingface/datasets/pull/4722.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4722.patch",
"merged_at": 1658335776000
} | `href="/docs/datasets/quickstart#audio"` implicitly goes to `href="/docs/datasets/{$LATEST_STABLE_VERSION}/quickstart#audio"`. Therefore, https://huggingface.co/docs/datasets/quickstart#audio #audio hashlink does not work since the new docs were not added to v2.3.2 (LATEST_STABLE_VERSION)
to preserve the version, it... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4722/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4722/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4721/comments | https://api.github.com/repos/huggingface/datasets/issues/4721/events | https://github.com/huggingface/datasets/issues/4721 | 1,310,253,552 | I_kwDODunzps5OGOHw | 4,721 | PyArrow Dataset error when calling `load_dataset` | {
"login": "piraka9011",
"id": 16828657,
"node_id": "MDQ6VXNlcjE2ODI4NjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/16828657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/piraka9011",
"html_url": "https://github.com/piraka9011",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! It looks like a bug in `pyarrow`. If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nTo achieve that you can try to lower the value of `max_shard_size` and also don't use `map` before `push_to_hub`.\r\n\r\nDo you have a minimum reproducible example that we can... | 1,658,279,763,000 | 1,658,499,107,000 | null | NONE | null | null | null | ## Describe the bug
I am fine tuning a wav2vec2 model following the script here using my own dataset: https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
Loading my Audio dataset from the hub which was originally generated from disk results in th... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4721/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4721/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4720/comments | https://api.github.com/repos/huggingface/datasets/issues/4720/events | https://github.com/huggingface/datasets/issues/4720 | 1,309,980,195 | I_kwDODunzps5OFLYj | 4,720 | Dataset Viewer issue for shamikbose89/lancaster_newsbooks | {
"login": "shamikbose",
"id": 50837285,
"node_id": "MDQ6VXNlcjUwODM3Mjg1",
"avatar_url": "https://avatars.githubusercontent.com/u/50837285?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shamikbose",
"html_url": "https://github.com/shamikbose",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | [
"It seems like the list of splits could not be obtained:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"shamikbose89/lancaster_newsbooks\", \"default\")\r\nUsing custom data configuration default\r\nTraceback (most recent call last):\r\n File \"/home/slesage/h... | 1,658,260,807,000 | 1,658,336,762,000 | null | NONE | null | null | null | ### Link
https://huggingface.co/datasets/shamikbose89/lancaster_newsbooks
### Description
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
I am able to use the dataset loading script locally and it also runs when I'm using the one from the hub, but the viewer sti... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4720/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4720/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4719/comments | https://api.github.com/repos/huggingface/datasets/issues/4719/events | https://github.com/huggingface/datasets/issues/4719 | 1,309,854,492 | I_kwDODunzps5OEssc | 4,719 | Issue loading TheNoob3131/mosquito-data dataset | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | [
"I am also getting a ValueError: 'Couldn't cast' at the bottom. Is this because of some delimiter issue? My dataset is on the Huggingface Hub. If you could look at it, that would be greatly appreciated.",
"Hi @thenerd31, thanks for reporting.\r\n\r\nPlease note that your issue is not caused by the Hugging Face Da... | 1,658,252,857,000 | 1,658,299,617,000 | null | NONE | null | null | null | 
So my dataset is public in the Huggingface Hub, but when I try to load it using the load_dataset command, it shows that it is downloading the files, but throws a ValueError. When I went to my directory to ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4719/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4719/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4718 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4718/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4718/comments | https://api.github.com/repos/huggingface/datasets/issues/4718/events | https://github.com/huggingface/datasets/pull/4718 | 1,309,520,453 | PR_kwDODunzps47prWR | 4,718 | Make Extractor accept Path as input | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,237,106,000 | 1,658,497,347,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4718",
"html_url": "https://github.com/huggingface/datasets/pull/4718",
"diff_url": "https://github.com/huggingface/datasets/pull/4718.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4718.patch",
"merged_at": 1658496583000
} | This PR:
- Makes `Extractor` accept instance of `Path` as input
- Removes unnecessary castings of `Path` to `str` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4718/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4718/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4717/comments | https://api.github.com/repos/huggingface/datasets/issues/4717/events | https://github.com/huggingface/datasets/issues/4717 | 1,309,512,483 | I_kwDODunzps5ODZMj | 4,717 | Dataset Viewer issue for LawalAfeez/englishreview-ds-mini | {
"login": "lawalAfeez820",
"id": 69974956,
"node_id": "MDQ6VXNlcjY5OTc0OTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/69974956?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lawalAfeez820",
"html_url": "https://github.com/lawalAfeez820",
"followers_url": "https://api.githu... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"It's currently working, as far as I understand\r\n\r\nhttps://huggingface.co/datasets/LawalAfeez/englishreview-ds-mini/viewer/LawalAfeez--englishreview-ds-mini/train\r\n\r\n<img width=\"1556\" alt=\"Capture d’écran 2022-07-19 à 09 24 01\" src=\"https://user-images.githubusercontent.com/1676121/179761130-2d7980b9... | 1,658,236,779,000 | 1,658,305,977,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
Unable to view the split data
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4717/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4717/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4716/comments | https://api.github.com/repos/huggingface/datasets/issues/4716/events | https://github.com/huggingface/datasets/pull/4716 | 1,309,455,838 | PR_kwDODunzps47pdbh | 4,716 | Support "tags" yaml tag | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"IMO `DatasetMetadata` shouldn't crash with attributes that it doesn't know, btw",
"Yea this PR is mostly to have a validation that this field contains a list of strings.\r\n\r\nRegarding unknown fields, the tagging app currently re... | 1,658,234,071,000 | 1,658,324,690,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4716",
"html_url": "https://github.com/huggingface/datasets/pull/4716",
"diff_url": "https://github.com/huggingface/datasets/pull/4716.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4716.patch",
"merged_at": 1658323916000
} | Added the "tags" YAML tag, so that users can specify data domain/topics keywords for dataset search | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4716/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4716/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4715/comments | https://api.github.com/repos/huggingface/datasets/issues/4715/events | https://github.com/huggingface/datasets/pull/4715 | 1,309,405,980 | PR_kwDODunzps47pSui | 4,715 | Fix POS tags | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are about missing content in the dataset cards or bad tags, and this is unrelated to this PR. Merging :)"
] | 1,658,231,574,000 | 1,658,235,274,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4715",
"html_url": "https://github.com/huggingface/datasets/pull/4715",
"diff_url": "https://github.com/huggingface/datasets/pull/4715.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4715.patch",
"merged_at": 1658234475000
} | We're now using `part-of-speech` and not `part-of-speech-tagging`, see discussion here: https://github.com/huggingface/datasets/commit/114c09aff2fa1519597b46fbcd5a8e0c0d3ae020#r78794777 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4715/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4715/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4714 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4714/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4714/comments | https://api.github.com/repos/huggingface/datasets/issues/4714/events | https://github.com/huggingface/datasets/pull/4714 | 1,309,265,682 | PR_kwDODunzps47o0YG | 4,714 | Fix named split sorting and remove unnecessary casting | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"hahaha what a timing, I added my comment right after you merged x)\r\n\r\nyou can ignore my (nit), it's fine",
"Sorry, just too sync... :sweat_smile: "
] | 1,658,224,108,000 | 1,658,482,785,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4714",
"html_url": "https://github.com/huggingface/datasets/pull/4714",
"diff_url": "https://github.com/huggingface/datasets/pull/4714.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4714.patch",
"merged_at": 1658481057000
} | This PR:
- makes `NamedSplit` sortable: so that `sorted()` can be called on them
- removes unnecessary `sorted()` on `dict.keys()`: `dict_keys` view is already like a `set`
- removes unnecessary casting of `NamedSplit` to `str` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4714/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4714/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4713/comments | https://api.github.com/repos/huggingface/datasets/issues/4713/events | https://github.com/huggingface/datasets/pull/4713 | 1,309,184,756 | PR_kwDODunzps47ojC1 | 4,713 | Document installation of sox OS dependency for audio | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,220,155,000 | 1,658,391,419,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4713",
"html_url": "https://github.com/huggingface/datasets/pull/4713",
"diff_url": "https://github.com/huggingface/datasets/pull/4713.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4713.patch",
"merged_at": 1658390655000
} | The `sox` OS package needs being installed manually using the distribution package manager.
This PR adds this explanation to the docs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4713/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4712/comments | https://api.github.com/repos/huggingface/datasets/issues/4712/events | https://github.com/huggingface/datasets/pull/4712 | 1,309,177,302 | PR_kwDODunzps47ohdr | 4,712 | Highlight non-commercial license in amazon_reviews_multi dataset card | {
"login": "sbroadhurst-hf",
"id": 108879611,
"node_id": "U_kgDOBn1e-w",
"avatar_url": "https://avatars.githubusercontent.com/u/108879611?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sbroadhurst-hf",
"html_url": "https://github.com/sbroadhurst-hf",
"followers_url": "https://api.github.c... | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4712). All of your documentation changes will be reflected on that endpoint."
] | 1,658,219,780,000 | 1,658,753,859,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4712",
"html_url": "https://github.com/huggingface/datasets/pull/4712",
"diff_url": "https://github.com/huggingface/datasets/pull/4712.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4712.patch",
"merged_at": null
} | Highlight that the licence granted by Amazon only covers non-commercial research use. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4712/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4712/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4711/comments | https://api.github.com/repos/huggingface/datasets/issues/4711/events | https://github.com/huggingface/datasets/issues/4711 | 1,309,138,570 | I_kwDODunzps5OB96K | 4,711 | Document how to create a dataset loading script for audio/vision | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [] | 1,658,217,820,000 | 1,658,217,820,000 | null | MEMBER | null | null | null | Currently, in our docs for Audio/Vision/Text, we explain how to:
- Load data
- Process data
However we only explain how to *Create a dataset loading script* for text data.
I think it would be useful that we add the same for Audio/Vision as these have some specificities different from Text.
See, for example:
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4711/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4711/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4710/comments | https://api.github.com/repos/huggingface/datasets/issues/4710/events | https://github.com/huggingface/datasets/pull/4710 | 1,308,958,525 | PR_kwDODunzps47ny0L | 4,710 | Add object detection processing tutorial | {
"login": "nateraw",
"id": 32437151,
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nateraw",
"html_url": "https://github.com/nateraw",
"followers_url": "https://api.github.com/users/natera... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Great idea! Now that we have more than one task, it makes sense to separate image classification and object detection so it'll be easier for users to follow.",
"@lhoestq do we want to do that in this PR, or should we merge it and l... | 1,658,204,626,000 | 1,658,434,235,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4710",
"html_url": "https://github.com/huggingface/datasets/pull/4710",
"diff_url": "https://github.com/huggingface/datasets/pull/4710.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4710.patch",
"merged_at": 1658433402000
} | The following adds a quick guide on how to process object detection datasets with `albumentations`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4710/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4710/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4709/comments | https://api.github.com/repos/huggingface/datasets/issues/4709/events | https://github.com/huggingface/datasets/issues/4709 | 1,308,633,093 | I_kwDODunzps5OACgF | 4,709 | WMT21 & WMT22 | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"Hi ! That would be awesome to have them indeed, thanks for opening this issue\r\n\r\nI just added you to the WMT org on the HF Hub if you're interested in adding those datasets.\r\n\r\nFeel free to create a dataset repository for each dataset and upload the data files there :) preferably in ZIP archives instead of... | 1,658,178,333,000 | 1,658,225,264,000 | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** WMT21 & WMT22
- **Description:** We are going to have three tracks: two small tasks and a large task.
The small tracks evaluate translation between fairly related languages and English (all pairs). The large track uses 101 languages.
- **Paper:** /
- **Data:** https://statmt.org/wmt... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4709/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4709/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4708/comments | https://api.github.com/repos/huggingface/datasets/issues/4708/events | https://github.com/huggingface/datasets/pull/4708 | 1,308,279,700 | PR_kwDODunzps47lewm | 4,708 | Fix require torchaudio and refactor test requirements | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,165,068,000 | 1,658,471,456,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4708",
"html_url": "https://github.com/huggingface/datasets/pull/4708",
"diff_url": "https://github.com/huggingface/datasets/pull/4708.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4708.patch",
"merged_at": 1658470691000
} | Currently there is a bug in `require_torchaudio` (indeed it is requiring `sox` instead):
```python
def require_torchaudio(test_case):
if find_spec("sox") is None:
...
```
The bug was introduced by:
- #3685
- Commit: https://github.com/huggingface/datasets/pull/3685/commits/b5a3e7122d49c4dcc9333b1d8d18a8... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4708/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4707/comments | https://api.github.com/repos/huggingface/datasets/issues/4707/events | https://github.com/huggingface/datasets/issues/4707 | 1,308,251,405 | I_kwDODunzps5N-lUN | 4,707 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Thanks for reporting. I refreshed the dataset viewer and it now works as expected.\r\n\r\nhttps://huggingface.co/datasets/TheNoob3131/mosquito-data\r\n\r\n<img width=\"1135\" alt=\"Capture d’écran 2022-07-18 à 13 15 22\" src=\"https://user-images.githubusercontent.com/1676121/179566497-e47f1a27-fd84-4a8d-9d7f-2e... | 1,658,164,039,000 | 1,658,173,486,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
Getting this error when trying to view dataset preview:
Message: 401, message='Unauthorized', url=URL('https://huggingface.co/datasets/TheNoob3131/mosquito-data/resolve/8aceebd6c4a359d216d10ef020868bd9e8c986dd/0_Africa_train.csv')
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4707/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4706/comments | https://api.github.com/repos/huggingface/datasets/issues/4706/events | https://github.com/huggingface/datasets/pull/4706 | 1,308,198,454 | PR_kwDODunzps47lNBg | 4,706 | Fix empty examples in xtreme dataset for bucc18 config | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I guess the report link is this instead: https://huggingface.co/datasets/xtreme/discussions/1"
] | 1,658,161,366,000 | 1,658,212,874,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4706",
"html_url": "https://github.com/huggingface/datasets/pull/4706",
"diff_url": "https://github.com/huggingface/datasets/pull/4706.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4706.patch",
"merged_at": 1658212157000
} | As reported in https://huggingface.co/muibk, there are empty examples in xtreme/bucc18.de
I applied your fix @mustaszewski
I also used a dict to make the dataset generation much faster | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4706/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4706/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4705/comments | https://api.github.com/repos/huggingface/datasets/issues/4705/events | https://github.com/huggingface/datasets/pull/4705 | 1,308,161,794 | PR_kwDODunzps47lFDo | 4,705 | Fix crd3 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,159,624,000 | 1,658,423,924,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4705",
"html_url": "https://github.com/huggingface/datasets/pull/4705",
"diff_url": "https://github.com/huggingface/datasets/pull/4705.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4705.patch",
"merged_at": 1658423190000
} | As reported in https://huggingface.co/datasets/crd3/discussions/1#62cc377073b2512b81662794, each split of the dataset was containing the same data. This issues comes from a bug in the dataset script
I fixed it and also uploaded the data to hf.co to make the dataset work in streaming mode | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4705/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4704/comments | https://api.github.com/repos/huggingface/datasets/issues/4704/events | https://github.com/huggingface/datasets/pull/4704 | 1,308,147,876 | PR_kwDODunzps47lCFt | 4,704 | Skip tests only for lz4/zstd params if not installed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,158,900,000 | 1,658,235,751,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4704",
"html_url": "https://github.com/huggingface/datasets/pull/4704",
"diff_url": "https://github.com/huggingface/datasets/pull/4704.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4704.patch",
"merged_at": 1658234958000
} | Currently, if `zstandard` or `lz4` are not installed, `test_compression_filesystems` and `test_streaming_dl_manager_extract_all_supported_single_file_compression_types` are skipped for all compression format parameters.
This PR fixes these tests, so that if `zstandard` or `lz4` are not installed, the tests are skipp... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4704/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4703/comments | https://api.github.com/repos/huggingface/datasets/issues/4703/events | https://github.com/huggingface/datasets/pull/4703 | 1,307,844,097 | PR_kwDODunzps47kABf | 4,703 | Make cast in `from_pandas` more robust | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,145,349,000 | 1,658,488,662,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4703",
"html_url": "https://github.com/huggingface/datasets/pull/4703",
"diff_url": "https://github.com/huggingface/datasets/pull/4703.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4703.patch",
"merged_at": 1658487924000
} | Make the cast in `from_pandas` more robust (as it was done for the packaged modules in https://github.com/huggingface/datasets/pull/4364)
This should be useful in situations like [this one](https://discuss.huggingface.co/t/loading-custom-audio-dataset-and-fine-tuning-model/8836/4). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4703/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4702/comments | https://api.github.com/repos/huggingface/datasets/issues/4702/events | https://github.com/huggingface/datasets/issues/4702 | 1,307,793,811 | I_kwDODunzps5N81mT | 4,702 | Domain specific dataset discovery on the Hugging Face hub | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/us... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Hi! I added a link to this issue in our internal request for adding keywords/topics to the Hub, which is identical to the `topic tags` solution. The `collections` solution seems too complex (as you point out). Regarding the `domain tags` solution, we primarily focus on machine learning, so I'm not sure if it's a g... | 1,658,142,843,000 | 1,658,243,891,000 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
## The problem
The datasets hub currently has `8,239` datasets. These datasets span a wide range of different modalities and tasks (currently with a bias towards textual data).
There are various ways of identifying datasets that may be releva... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4702/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4702/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4701/comments | https://api.github.com/repos/huggingface/datasets/issues/4701/events | https://github.com/huggingface/datasets/pull/4701 | 1,307,689,625 | PR_kwDODunzps47jeE9 | 4,701 | Added more information in the README about contributors of the Arabic Speech Corpus | {
"login": "nawarhalabi",
"id": 2845798,
"node_id": "MDQ6VXNlcjI4NDU3OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2845798?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nawarhalabi",
"html_url": "https://github.com/nawarhalabi",
"followers_url": "https://api.github.com/us... | [] | open | false | null | [] | null | [] | 1,658,137,683,000 | 1,658,212,646,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4701",
"html_url": "https://github.com/huggingface/datasets/pull/4701",
"diff_url": "https://github.com/huggingface/datasets/pull/4701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4701.patch",
"merged_at": null
} | Added more information in the README about contributors and encouraged reading the thesis for more infos | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4701/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4701/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4700/comments | https://api.github.com/repos/huggingface/datasets/issues/4700/events | https://github.com/huggingface/datasets/pull/4700 | 1,307,599,161 | PR_kwDODunzps47jKNx | 4,700 | Support extract lz4 compressed data files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,133,691,000 | 1,658,155,439,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4700",
"html_url": "https://github.com/huggingface/datasets/pull/4700",
"diff_url": "https://github.com/huggingface/datasets/pull/4700.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4700.patch",
"merged_at": 1658154707000
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4700/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4700/timeline | null | null | true |
End of preview. Expand in Data Studio
No dataset card yet
- Downloads last month
- 22