
Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation
Paper
•
2402.18334
•
Published
•
12
Bonito is an open-source model for conditional task generation: the task of converting unannotated text into task-specific training datasets for instruction tuning. This repo is a lightweight library for Bonito to easily create synthetic datasets built on top of the Hugging Face transformers and vllm libraries.
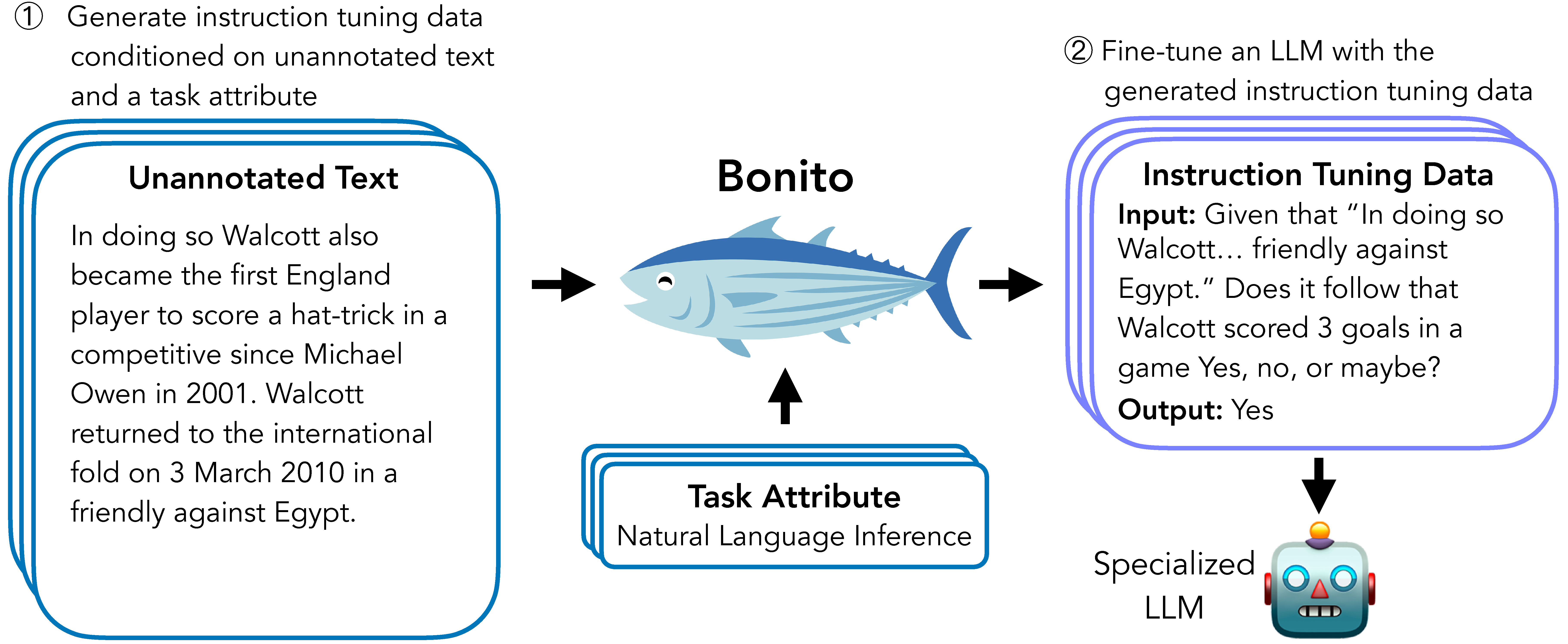
Because of the training data limitations, this version supports only the 3 task types
To generate synthetic instruction tuning dataset using Bonito, you can use the following code:
pip3 install bonito-llm
from pprint import pprint
from datasets import Dataset
from vllm import SamplingParams
from transformers import set_seed
from bonito import Bonito
unannotated_paragraph = """灌区以往的闸门控制系统在实际应用过程中普遍以人工操作为主,容易受到多种因素的影响,不可避免出现较多缺陷。如操作人员自身的综合能力、业务水平、工作态度等对工作质量和效率产生较大影响;工作人员实践操作中遇到极端气候、工作环境恶劣等问题,大大增加了工作难度,并存在较多安全隐患。"""
pprint(unannotated_paragraph)
bonito = Bonito("kitsdk/bonito-chinese-v1")
set_seed(2)
def convert_to_dataset(text):
dataset = Dataset.from_list([{"input": text}])
return dataset
sampling_params = SamplingParams(max_tokens=256, top_p=0.95, temperature=0.5, n=1)
synthetic_dataset = bonito.generate_tasks(
convert_to_dataset(unannotated_paragraph),
context_col="input",
task_type="mcqa",
sampling_params=sampling_params
)
pprint("----Generated Instructions----")
pprint(f'Input: {synthetic_dataset[0]["input"]}')
pprint(f'Output: {synthetic_dataset[0]["output"]}')
Base model
Qwen/Qwen2.5-3B