
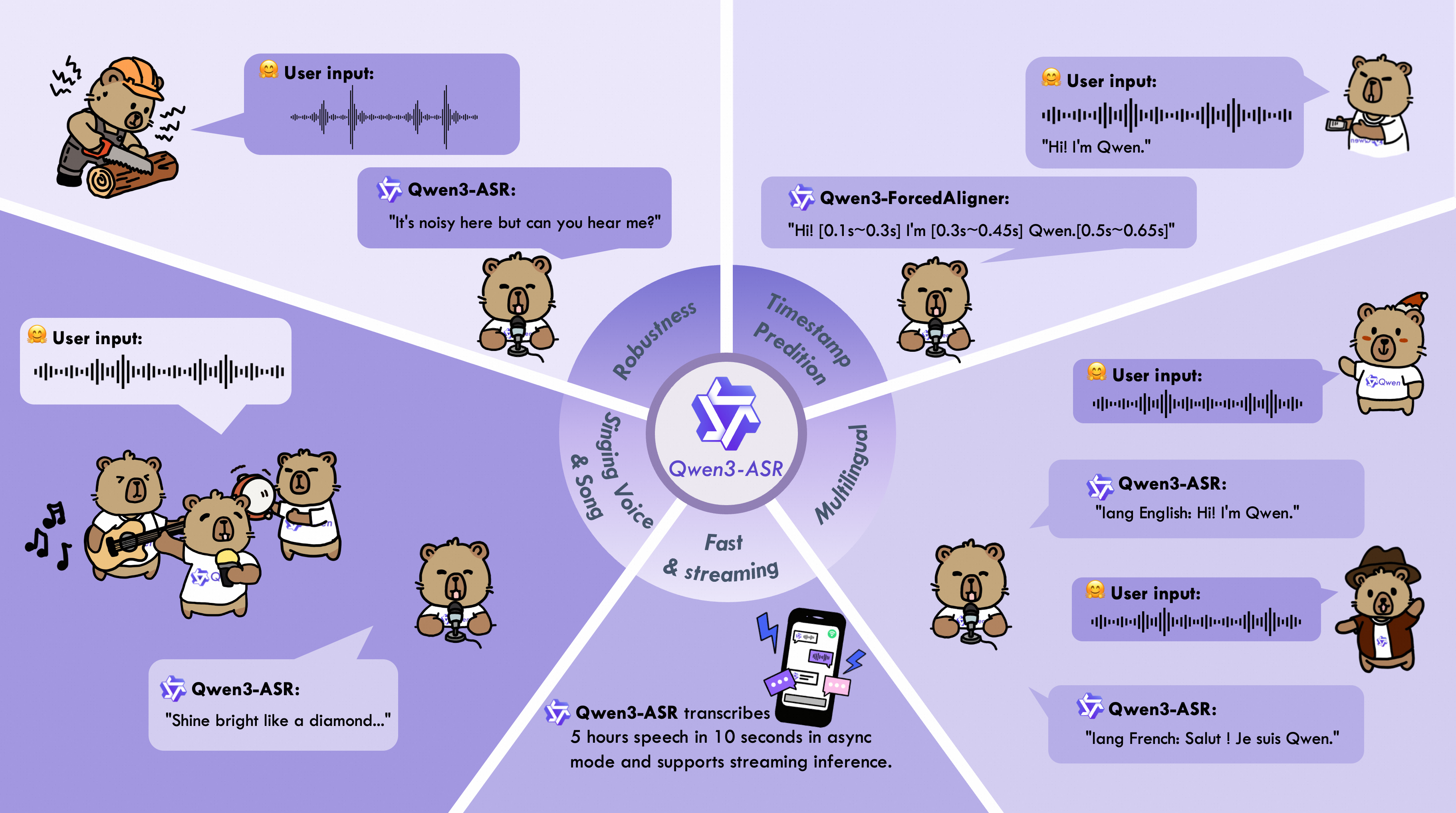
Qwen3-ASR Technical Report
Paper • 2601.21337 • Published • 37
🚨 IMPORTANT NOTE: This repository contains the GGUF-format weights for the Qwen3-ASR-Lyrics-Viet models. These files are highly optimized for CPU and edge-device inference using pure C/C++ without requiring heavy Python dependencies or dedicated GPUs.
For the original PyTorch/Safetensors weights (for fine-tuning or vLLM deployment), please visit the base repositories:
These models are fine-tuned versions of the original Qwen3-ASR models. They have been fine-tuned using LoRA on a dataset of 50,000 Vietnamese music samples to specialize in accurately transcribing Vietnamese lyrics. While they retain the powerful capabilities of the original models (supporting 30+ languages), they are heavily optimized for Vietnamese singing voices, speech, and songs with BGM.
We provide both f16 (highest accuracy) and q8_0 (8-bit quantized, fast & lightweight) formats. Choose the one that best fits your hardware:
| Model Version | File Name | Size | Recommendation |
|---|---|---|---|
| 0.6B (Fastest) | Qwen3-ASR-0.6B-Lyrics-Viet-q8_0.gguf |
~630 MB | Best for standard laptops/PCs. Ultra-fast inference. |
| 0.6B (High Acc) | Qwen3-ASR-0.6B-Lyrics-Viet-f16.gguf |
~1.8 GB | Best if you want original accuracy with small memory footprint. |
| 1.7B (Smarter) | Qwen3-ASR-1.7B-Lyrics-Viet-q8_0.gguf |
~1.8 GB | Best balance between high accuracy and performance. |
| 1.7B (Max Acc) | Qwen3-ASR-1.7B-Lyrics-Viet-f16.gguf |
~3.4 GB | Best for powerful machines or GPU offloading. |
| Model Name | WER (%) Case-Sensitive | WER (%) Lowercase | CER (%) Case-Sensitive | CER (%) Lowercase |
|---|---|---|---|---|
| Qwen3-ASR-0.6B-Base | 41.76 | 29.45 | 19.86 | 16.3 |
| Qwen3-ASR-0.6B-Lyrics-Viet | 29.19 | 24.91 | 15.98 | 14.74 |
| Qwen3-ASR-1.7B-Base | 34.28 | 21.27 | 15.61 | 12.04 |
| Qwen3-ASR-1.7B-Lyrics-Viet | 24.57 | 19.26 | 13.19 | 11.72 |
The easiest way to use Qwen3-ASR is to install the qwen-asr Python package from PyPI. This will pull in the required runtime dependencies and allow you to load any released Qwen3-ASR model. If you’d like to simplify environment setup further, you can also use our official Docker image. The qwen-asr package provides two backends: the transformers backend and the vLLM backend. For usage instructions for different backends, please refer to Python Package Usage. We recommend using a fresh, isolated environment to avoid dependency conflicts with existing packages. You can create a clean Python 3.12 environment like this:
conda create -n qwen3-asr python=3.12 -y
conda activate qwen3-asr
Run the following command to get the minimal installation with transformers-backend support:
pip install -U qwen-asr
To enable the vLLM backend for faster inference and streaming support, run:
pip install -U qwen-asr[vllm]
If you want to develop or modify the code locally, install from source in editable mode:
git clone https://github.com/QwenLM/Qwen3-ASR.git
cd Qwen3-ASR
pip install -e .
# support vLLM backend
# pip install -e ".[vllm]"
Additionally, we recommend using FlashAttention 2 to reduce GPU memory usage and accelerate inference speed, especially for long inputs and large batch sizes.
pip install -U flash-attn --no-build-isolation
If your machine has less than 96GB of RAM and lots of CPU cores, run:
MAX_JOBS=4 pip install -U flash-attn --no-build-isolation
Also, you should have hardware that is compatible with FlashAttention 2. Read more about it in the official documentation of the FlashAttention repository. FlashAttention 2 can only be used when a model is loaded in torch.float16 or torch.bfloat16.
The qwen-asr package provides two backends: transformers backend and vLLM backend. You can pass audio inputs as a local path, a URL, base64 data, or a (np.ndarray, sr) tuple, and run batch inference. To quickly try Qwen3-ASR, you can use Qwen3ASRModel.from_pretrained(...) for the transformers backend with the following code:
import torch
from qwen_asr import Qwen3ASRModel
model = Qwen3ASRModel.from_pretrained(
"sunbv56/Qwen3-ASR-1.7B-Lyrics-Viet",
dtype=torch.bfloat16,
device_map="cuda:0",
# attn_implementation="flash_attention_2",
max_inference_batch_size=32, # Batch size limit for inference. -1 means unlimited. Smaller values can help avoid OOM.
max_new_tokens=256, # Maximum number of tokens to generate. Set a larger value for long audio input.
)
results = model.transcribe(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
language="Vietnamese", # set "None" to auto-detect the language
)
print(results[0].language)
print(results[0].text)
During evaluation, we ran inference for all models with dtype=torch.bfloat16 and set max_new_tokens=1024 using vLLM. Greedy search was used for all decoding, and none of the tests specified a language parameter. The detailed evaluation results are shown below.
| GPT-4o -Transcribe |
Gemini-2.5 -Pro |
Doubao-ASR | Whisper -large-v3 |
Fun-ASR -MLT-Nano |
Qwen3-ASR -0.6B |
Qwen3-ASR -1.7B |
||
|---|---|---|---|---|---|---|---|---|
| English (en) | ||||||||
| Librispeech clean | other |
1.39 | 3.75 | 2.89 | 3.56 | 2.78 | 5.70 | 1.51 | 3.97 | 1.68 | 4.03 | 2.11 | 4.55 | 1.63 | 3.38 | |
| GigaSpeech | 25.50 | 9.37 | 9.55 | 9.76 | - | 8.88 | 8.45 | |
| CV-en | 9.08 | 14.49 | 13.78 | 9.90 | 9.90 | 9.92 | 7.39 | |
| Fleurs-en | 2.40 | 2.94 | 6.31 | 4.08 | 5.49 | 4.39 | 3.35 | |
| MLS-en | 5.12 | 3.68 | 7.09 | 4.87 | - | 6.00 | 4.58 | |
| Tedlium | 7.69 | 6.15 | 4.91 | 6.84 | - | 3.85 | 4.50 | |
| VoxPopuli | 10.29 | 11.36 | 12.12 | 12.05 | - | 9.96 | 9.15 | |
| Chinese (zh) | ||||||||
| WenetSpeech net | meeting |
15.30 | 32.27 | 14.43 | 13.47 | N/A | 9.86 | 19.11 | 6.35 | - | 5.97 | 6.88 | 4.97 | 5.88 | |
| AISHELL-2-test | 4.24 | 11.62 | 2.85 | 5.06 | - | 3.15 | 2.71 | |
| SpeechIO | 12.86 | 5.30 | 2.93 | 7.56 | - | 3.44 | 2.88 | |
| Fleurs-zh | 2.44 | 2.71 | 2.69 | 4.09 | 3.51 | 2.88 | 2.41 | |
| CV-zh | 6.32 | 7.70 | 5.95 | 12.91 | 6.20 | 6.89 | 5.35 | |
| Chinese Dialect | ||||||||
| KeSpeech | 26.87 | 24.71 | 5.27 | 28.79 | - | 7.08 | 5.10 | |
| Fleurs-yue | 4.98 | 9.43 | 4.98 | 9.18 | - | 5.79 | 3.98 | |
| CV-yue | 11.36 | 18.76 | 13.20 | 16.23 | - | 9.50 | 7.57 | |
| CV-zh-tw | 6.32 | 7.31 | 4.06 | 7.84 | - | 5.59 | 3.77 | |
| WenetSpeech-Yue short | long |
15.62 | 25.29 | 25.19 | 11.23 | 9.74 | 11.40 | 32.26 | 46.64 | - | - | 7.54 | 9.92 | 5.82 | 8.85 | |
| WenetSpeech-Chuan easy | hard |
34.81 | 53.98 | 43.79 | 67.30 | 11.40 | 20.20 | 14.35 | 26.80 | - | - | 13.92 | 24.45 | 11.99 | 21.63 | |
| GPT-4o -Transcribe |
Gemini-2.5 -Pro |
Doubao-ASR | Whisper -large-v3 |
Fun-ASR -MLT-Nano |
Qwen3-ASR -0.6B |
Qwen3-ASR -1.7B |
|
|---|---|---|---|---|---|---|---|
| Accented English | |||||||
| Dialog-Accented English | 28.56 | 23.85 | 20.41 | 21.30 | 19.96 | 16.62 | 16.07 |
| Chinese Mandarin | |||||||
| Elders&Kids | 14.27 | 36.93 | 4.17 | 10.61 | 4.54 | 4.48 | 3.81 |
| ExtremeNoise | 36.11 | 29.06 | 17.04 | 63.17 | 36.55 | 17.88 | 16.17 |
| TongueTwister | 20.87 | 4.97 | 3.47 | 16.63 | 9.02 | 4.06 | 2.44 |
| Dialog-Mandarin | 20.73 | 12.50 | 6.61 | 14.01 | 7.32 | 7.06 | 6.54 |
| Chinese Dialect | |||||||
| Dialog-Cantonese | 16.05 | 14.98 | 7.56 | 31.04 | 5.85 | 4.80 | 4.12 |
| Dialog-Chinese Dialects | 45.37 | 47.70 | 19.85 | 44.55 | 19.41 | 18.24 | 15.94 |
Dialect coverage: Results for Dialog-Accented English are averaged over 16 accents, and results for Dialog-Chinese Dialects are averaged over 22 Chinese dialects.
| GLM-ASR -Nano-2512 |
Whisper -large-v3 |
Fun-ASR -MLT-Nano |
Qwen3-ASR -0.6B |
Qwen3-ASR -1.7B |
|
|---|---|---|---|---|---|
| Open-sourced Benchmarks | |||||
| MLS | 13.32 | 8.62 | 28.70 | 13.19 | 8.55 |
| CommonVoice | 19.40 | 10.77 | 17.25 | 12.75 | 9.18 |
| MLC-SLM | 34.93 | 15.68 | 29.94 | 15.84 | 12.74 |
| Fleurs | 16.08 | 5.27 | 10.03 | 7.57 | 4.90 |
| Fleurs† | 20.05 | 6.85 | 31.89 | 10.37 | 6.62 |
| Fleurs†† | 24.83 | 8.16 | 47.84 | 21.80 | 12.60 |
| Qwen-ASR Internal Benchmarks | |||||
| News-Multilingual | 49.40 | 14.80 | 65.07 | 17.39 | 12.80 |
Language coverage: MLS includes 8 languages: {da, de, en, es, fr, it, pl, pt}.
CommonVoice includes 13 languages: {en, zh, yue, zh_TW, ar, de, es, fr, it, ja, ko, pt, ru}.
MLC-SLM includes 11 languages: {en, fr, de, it, pt, es, ja, ko, ru, th, vi}.
Fleurs includes 12 languages: {en, zh, yue, ar, de, es, fr, it, ja, ko, pt, ru }.
Fleurs† includes 8 additional languages beyond Fleurs: {hi, id, ms, nl, pl, th, tr, vi}.
Fleurs†† includes 10 additional languages beyond Fleurs†: {cs, da, el, fa, fi, fil, hu, mk, ro, sv}.
News-Multilingual includes 15 languages: {ar, de, es, fr, hi, id, it, ja, ko, nl, pl, pt, ru, th, vi}.
| Whisper-large-v3 | Qwen3-ASR-0.6B | Qwen3-ASR-1.7B | |
|---|---|---|---|
| MLS | 99.9 | 99.3 | 99.9 |
| CommonVoice | 92.7 | 98.2 | 98.7 |
| MLC-SLM | 89.2 | 92.7 | 94.1 |
| Fleurs | 94.6 | 97.1 | 98.7 |
| Avg. | 94.1 | 96.8 | 97.9 |
Language coverage: The language sets follow Multilingual ASR Benchmarks. Here, Fleurs corresponds to Fleurs†† in Multilingual ASR Benchmarks and covers 30 languages.
| GPT-4o -Transcribe |
Gemini-2.5 -Pro |
Doubao-ASR -1.0 |
Whisper -large-v3 |
Fun-ASR-MLT -Nano |
Qwen3-ASR -1.7B |
|
|---|---|---|---|---|---|---|
| Singing | ||||||
| M4Singer | 16.77 | 20.88 | 7.88 | 13.58 | 7.29 | 5.98 |
| MIR-1k-vocal | 11.87 | 9.85 | 6.56 | 11.71 | 8.17 | 6.25 |
| Opencpop | 7.93 | 6.49 | 3.80 | 9.52 | 2.98 | 3.08 |
| Popcs | 32.84 | 15.13 | 8.97 | 13.77 | 9.42 | 8.52 |
| Songs with BGM | ||||||
| EntireSongs-en | 30.71 | 12.18 | 33.51 | N/A | N/A | 14.60 |
| EntireSongs-zh | 34.86 | 18.68 | 23.99 | N/A | N/A | 13.91 |
| Model | Infer. Mode | Librispeech | Fleurs-en | Fleurs-zh | Avg. |
|---|---|---|---|---|---|
| Qwen3-ASR-1.7B | Offline | 1.63 | 3.38 | 3.35 | 2.41 | 2.69 |
| Streaming | 1.95 | 4.51 | 4.02 | 2.84 | 3.33 | |
| Qwen3-ASR-0.6B | Offline | 2.11 | 4.55 | 4.39 | 2.88 | 3.48 |
| Streaming | 2.54 | 6.27 | 5.38 | 3.40 | 4.40 |
| Monotonic-Aligner | NFA | WhisperX | Qwen3-ForcedAligner-0.6B | |
|---|---|---|---|---|
| MFA-Labeled Raw | ||||
| Chinese | 161.1 | 109.8 | - | 33.1 |
| English | - | 107.5 | 92.1 | 37.5 |
| French | - | 100.7 | 145.3 | 41.7 |
| German | - | 122.7 | 165.1 | 46.5 |
| Italian | - | 142.7 | 155.5 | 75.5 |
| Japanese | - | - | - | 42.2 |
| Korean | - | - | - | 37.2 |
| Portuguese | - | - | - | 38.4 |
| Russian | - | 200.7 | - | 40.2 |
| Spanish | - | 124.7 | 108.0 | 36.8 |
| Avg. | 161.1 | 129.8 | 133.2 | 42.9 |
| MFA-Labeled Concat-300s | ||||
| Chinese | 1742.4 | 235.0 | - | 36.5 |
| English | - | 226.7 | 227.2 | 58.6 |
| French | - | 230.6 | 2052.2 | 53.4 |
| German | - | 220.3 | 993.4 | 62.4 |
| Italian | - | 290.5 | 5719.4 | 81.6 |
| Japanese | - | - | - | 81.3 |
| Korean | - | - | - | 42.2 |
| Portuguese | - | - | - | 50.0 |
| Russian | - | 283.3 | - | 43.0 |
| Spanish | - | 240.2 | 4549.9 | 39.6 |
| Cross-lingual | - | - | - | 34.2 |
| Avg. | 1742.4 | 246.7 | 2708.4 | 52.9 |
| Human-Labeled | ||||
| Raw | 49.9 | 88.6 | - | 27.8 |
| Raw-Noisy | 53.3 | 89.5 | - | 41.8 |
| Concat-60s | 51.1 | 86.7 | - | 25.3 |
| Concat-300s | 410.8 | 140.0 | - | 24.8 |
| Concat-Cross-lingual | - | - | - | 42.5 |
| Avg. | 141.3 | 101.2 | - | 32.4 |
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
@article{Qwen3-ASR,
title={Qwen3-ASR Technical Report},
author={Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, Junyang Lin},
journal={arXiv preprint arXiv:2601.21337},
year={2026}
}
8-bit
16-bit
Base model
Qwen/Qwen3-ASR-0.6B