
Routing Matters in MoE: Scaling Diffusion Transformers with Explicit Routing Guidance
Paper • 2510.24711 • Published • 20
![]()
Yujie Wei1, Shiwei Zhang2*, Hangjie Yuan3, Yujin Han4, Zhekai Chen4,5, Jiayu Wang2, Difan Zou4, Xihui Liu4,5, Yingya Zhang2, Yu Liu2, Hongming Shan1†
(*Project Leader, †Corresponding Author)
1Fudan University 2Tongyi Lab, Alibaba Group 3Zhejiang University 4The University of Hong Kong 5MMLab
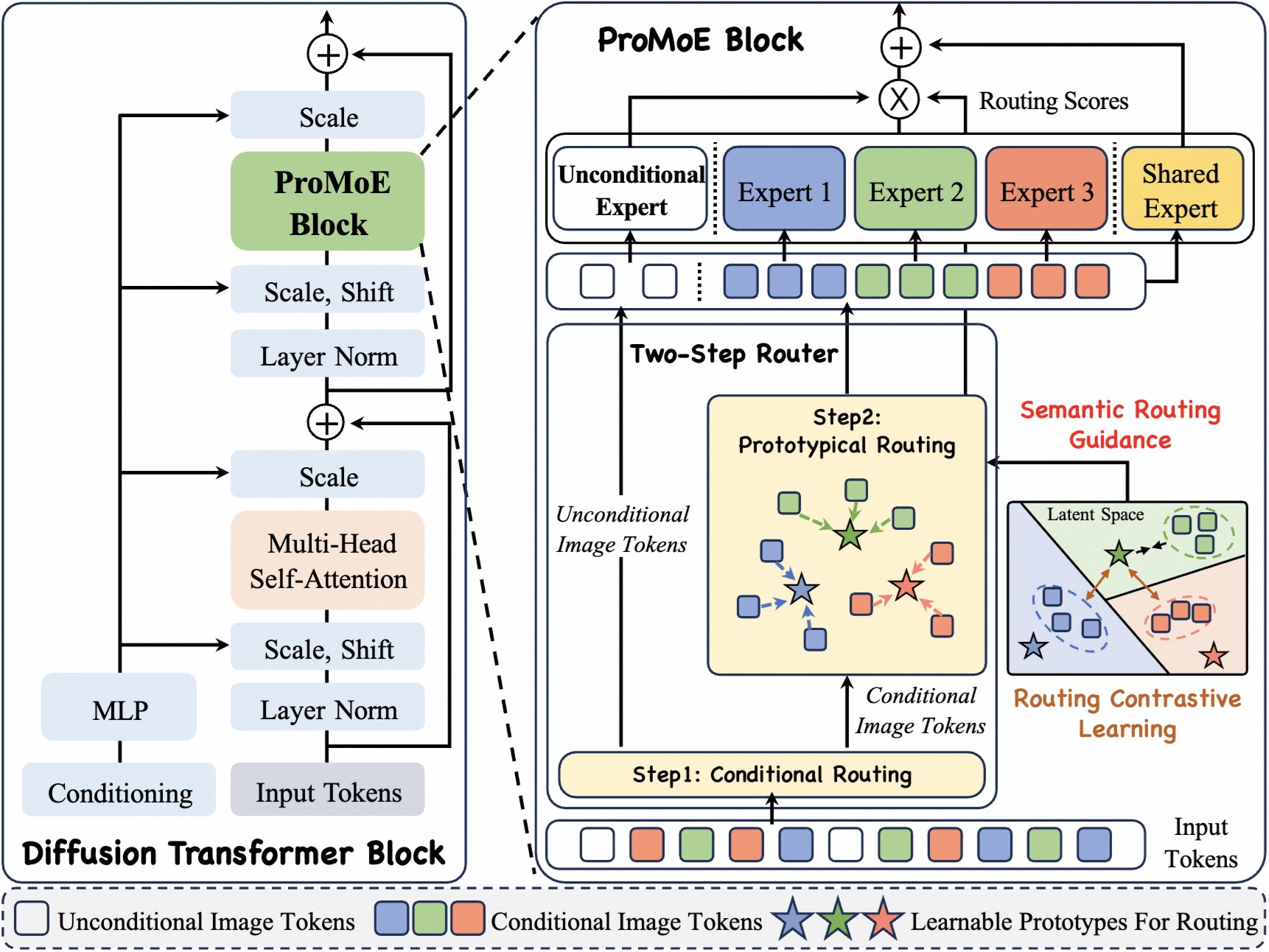
ProMoE is an MoE framework that employs a two-step router with explicit routing guidance to promote expert specialization for scaling Diffusion Transformers.
This codebase supports:
We have released the model weights, generated 50K images, and corresponding evaluation results on both Hugging Face and ModelScope.
| Model | Platform | Weights | 50K Images | Eval Results (CFG=1.0) | Eval Results (CFG=1.5) |
|---|---|---|---|---|---|
| ProMoE-B-Flow (500K) |
Hugging Face ModelScope |
Link Link |
cfg=1.0, cfg=1.5 cfg=1.0, cfg=1.5 |
FID 24.44, IS 60.38 FID 24.44, IS 60.38 |
FID 6.39, IS 154.21 FID 6.39, IS 154.21 |
| ProMoE-L-Flow (500K) |
Hugging Face ModelScope |
Link Link |
cfg=1.0, cfg=1.5 cfg=1.0, cfg=1.5 |
FID 11.61, IS 100.82 FID 11.61, IS 100.82 |
FID 2.79, IS 244.21 FID 2.79, IS 244.21 |
| ProMoE-XL-Flow (500K) |
Hugging Face ModelScope |
Link Link |
cfg=1.0, cfg=1.5 cfg=1.0, cfg=1.5 |
FID 9.44, IS 114.94 FID 9.44, IS 114.94 |
FID 2.59, IS 265.62 FID 2.59, IS 265.62 |
conda create -n promoe python=3.10 -y
conda activate promoe
pip install -r requirements.txt
Download ImageNet dataset, and modify cfg.data_path in config.py.
For faster training and more efficient GPU usage, you can precompute VAE latents and train with cfg.use_pre_latents=True.
Run latent preprocessing:
# bash
ImageNet_path=/path/to/ImageNet
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python preprocess/preprocess_vae.py --latent_save_root "$ImageNet_path/sd-vae-ft-mse_Latents_256img_npz"
Training is launched via train.py with a YAML config:
python train.py --config configs/004_ProMoE_L.yaml
Notes:
models/models_ProMoE_EC.py.configs directory.qk_norm=False. For extended training steps (>2M steps), we suggest enabling qk_norm=True to ensure training stability.Image generation is performed via the sample.py script, utilizing the same YAML configuration file used for training.
# use default setting
CUDA_VISIBLE_DEVICES=0 python sample.py --config configs/004_ProMoE_L.yaml
# use custom setting
CUDA_VISIBLE_DEVICES=0 python sample.py \
--config configs/004_ProMoE_L.yaml \
--step_list_for_sample 200000,300000 \
--guide_scale_list 1.0,1.5,4.0 \
--num_fid_samples 10000
Notes:
CUDA_VISIBLE_DEVICES or by adding sample_gpu_ids in the configuration file. Please be aware that multi-GPU inference produces a globally different random sequence (e.g., class labels) compared to single-GPU inference.sample/ directory within the same parent directory as the checkpoint folder. Filenames include both the sample index and class label.cfg.save_inception_features=True to save Inception features and reduce cfg.save_img_num.We follow the standard evaluation protocol outlined in openai's guided-diffusion. All relevant code is located in the evaluation directory.
Since the evaluation pipeline relies on TensorFlow, we strongly recommend creating a dedicated environment to avoid dependency conflicts.
conda create -n promoe_eval python=3.9 -y
conda activate promoe_eval
cd evaluation
pip install -r requirements.txt
conda install -c conda-forge cudatoolkit=11.2 cudnn=8.1.0
Download the reference statistics file VIRTUAL_imagenet256_labeled.npz (for 256x256 images) and place it in the evaluation directory.
To calculate the metrics, run the evaluation script by specifying the path to your folder of generated images.
CUDA_VISIBLE_DEVICES=0 python run_eval.py /path/to/generated/images
This code is built on top of DiffMoE, DiT, and guided-diffusion. We thank the authors for their great work.
If you find this code useful for your research, please cite our paper:
@inproceedings{wei2026promoe,
title={Routing Matters in MoE: Scaling Diffusion Transformers with Explicit Routing Guidance},
author={Wei, Yujie and Zhang, Shiwei and Yuan, Hangjie and Han, Yujin and Chen, Zhekai and Wang, Jiayu and Zou, Difan and Liu, Xihui and Zhang, Yingya and Liu, Yu and others},
booktitle={International Conference on Learning Representations},
year={2026}
}