
url stringlengths 58 61 | repository_url stringclasses 1 value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.12B | node_id stringlengths 18 32 | number int64 1 3.68k | title stringlengths 1 276 | user dict | labels list | state stringclasses 2 values | locked bool 1 class | assignee dict | assignees list | milestone null | comments sequence | created_at int64 1.59k 1,644B | updated_at int64 1.59k 1,694B | closed_at int64 1.59k 1,690B ⌀ | author_association stringclasses 3 values | active_lock_reason null | draft bool 2 classes | pull_request dict | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 2 values | is_pull_request bool 2 classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3678/comments | https://api.github.com/repos/huggingface/datasets/issues/3678/events | https://github.com/huggingface/datasets/pull/3678 | 1,123,402,426 | PR_kwDODunzps4yCt91 | 3,678 | Add code example in wikipedia card | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,643,911,742,000 | 1,645,434,896,000 | 1,643,980,899,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3678",
"html_url": "https://github.com/huggingface/datasets/pull/3678",
"diff_url": "https://github.com/huggingface/datasets/pull/3678.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3678.patch",
"merged_at": 1643980899000
} | Close #3292. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3678/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3677/comments | https://api.github.com/repos/huggingface/datasets/issues/3677/events | https://github.com/huggingface/datasets/issues/3677 | 1,123,192,866 | I_kwDODunzps5C8pAi | 3,677 | Discovery cannot be streamed anymore | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Seems like a regression from https://github.com/huggingface/datasets/pull/2843\r\n\r\nOr maybe it's an issue with the hosting. I don't think so, though, because https://www.dropbox.com/s/aox84z90nyyuikz/discovery.zip seems to work as expected\r\n\r\n",
"Hi @severo, thanks for reporting.\r\n\r\nSome servers do no... | 1,643,900,523,000 | 1,644,511,884,000 | 1,644,511,884,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
iterable_dataset = load_dataset("discovery", name="discovery", split="train", streaming=True)
list(iterable_dataset.take(1))
```
## Expected results
The first row of the train split.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 365, in __iter__
for key, example in self._iter():
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 362, in _iter
yield from ex_iterable
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 272, in __iter__
yield from islice(self.ex_iterable, self.n)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 79, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/discovery/542fab7a9ddc1d9726160355f7baa06a1ccc44c40bc8e12c09e9bc743aca43a2/discovery.py", line 333, in _generate_examples
with open(data_file, encoding="utf8") as f:
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/streaming.py", line 64, in wrapper
return function(*args, use_auth_token=use_auth_token, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/utils/streaming_download_manager.py", line 369, in xopen
file_obj = fsspec.open(file, mode=mode, *args, **kwargs).open()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 456, in open
return open_files(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 288, in open_files
fs, fs_token, paths = get_fs_token_paths(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/core.py", line 611, in get_fs_token_paths
fs = filesystem(protocol, **inkwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/registry.py", line 253, in filesystem
return cls(**storage_options)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/spec.py", line 68, in __call__
obj = super().__call__(*args, **kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/zip.py", line 57, in __init__
self.zip = zipfile.ZipFile(self.fo)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1257, in __init__
self._RealGetContents()
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 1320, in _RealGetContents
endrec = _EndRecData(fp)
File "/home/slesage/.pyenv/versions/3.9.6/lib/python3.9/zipfile.py", line 263, in _EndRecData
fpin.seek(0, 2)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py", line 676, in seek
raise ValueError("Cannot seek streaming HTTP file")
ValueError: Cannot seek streaming HTTP file
```
## Environment info
- `datasets` version: 1.18.3
- Platform: Linux-5.11.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3677/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3676/comments | https://api.github.com/repos/huggingface/datasets/issues/3676/events | https://github.com/huggingface/datasets/issues/3676 | 1,123,096,362 | I_kwDODunzps5C8Rcq | 3,676 | `None` replaced by `[]` after first batch in map | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"It looks like this is because of this behavior in pyarrow:\r\n```python\r\nimport pyarrow as pa\r\n\r\narr = pa.array([None, [0]])\r\nreconstructed_arr = pa.ListArray.from_arrays(arr.offsets, arr.values)\r\nprint(reconstructed_arr.to_pylist())\r\n# [[], [0]]\r\n```\r\n\r\nIt seems that `arr.offsets` can reconstruc... | 1,643,895,408,000 | 1,666,962,800,000 | 1,666,962,800,000 | MEMBER | null | null | null | Sometimes `None` can be replaced by `[]` when running map:
```python
from datasets import Dataset
ds = Dataset.from_dict({"a": range(4)})
ds = ds.map(lambda x: {"b": [[None, [0]]]}, batched=True, batch_size=1, remove_columns=["a"])
print(ds.to_pandas())
# b
# 0 [None, [0]]
# 1 [[], [0]]
# 2 [[], [0]]
# 3 [[], [0]]
```
This issue has been experienced when running the `run_qa.py` example from `transformers` (see issue https://github.com/huggingface/transformers/issues/15401)
This can be due to a bug in when casting `None` in nested lists. Casting only happens after the first batch, since the first batch is used to infer the feature types.
cc @sgugger | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3676/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 2
} | https://api.github.com/repos/huggingface/datasets/issues/3676/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3675/comments | https://api.github.com/repos/huggingface/datasets/issues/3675/events | https://github.com/huggingface/datasets/issues/3675 | 1,123,078,408 | I_kwDODunzps5C8NEI | 3,675 | Add CodeContests dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [
"@mariosasko Can I take this up?",
"This dataset is now available here: https://huggingface.co/datasets/deepmind/code_contests."
] | 1,643,894,400,000 | 1,658,315,225,000 | 1,658,315,225,000 | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** CodeContests
- **Description:** CodeContests is a competitive programming dataset for machine-learning.
- **Paper:**
- **Data:** https://github.com/deepmind/code_contests
- **Motivation:** This dataset was used when training [AlphaCode](https://deepmind.com/blog/article/Competitive-programming-with-AlphaCode).
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3675/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3675/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3674/comments | https://api.github.com/repos/huggingface/datasets/issues/3674/events | https://github.com/huggingface/datasets/pull/3674 | 1,123,027,874 | PR_kwDODunzps4yBe17 | 3,674 | Add FrugalScore metric | {
"login": "moussaKam",
"id": 28675016,
"node_id": "MDQ6VXNlcjI4Njc1MDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/28675016?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moussaKam",
"html_url": "https://github.com/moussaKam",
"followers_url": "https://api.github.com/users/moussaKam/followers",
"following_url": "https://api.github.com/users/moussaKam/following{/other_user}",
"gists_url": "https://api.github.com/users/moussaKam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moussaKam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moussaKam/subscriptions",
"organizations_url": "https://api.github.com/users/moussaKam/orgs",
"repos_url": "https://api.github.com/users/moussaKam/repos",
"events_url": "https://api.github.com/users/moussaKam/events{/privacy}",
"received_events_url": "https://api.github.com/users/moussaKam/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq \r\n\r\nThe model used by default (`moussaKam/frugalscore_tiny_bert-base_bert-score`) is a tiny model.\r\n\r\nI still want to make one modification before merging.\r\nI would like to load the model checkpoint once. Do you think it's a good idea if I load it in `_download_and_prepare`? In this case should ... | 1,643,891,332,000 | 1,645,459,124,000 | 1,645,459,124,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3674",
"html_url": "https://github.com/huggingface/datasets/pull/3674",
"diff_url": "https://github.com/huggingface/datasets/pull/3674.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3674.patch",
"merged_at": 1645459124000
} | This pull request add FrugalScore metric for NLG systems evaluation.
FrugalScore is a reference-based metric for NLG models evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
Paper: https://arxiv.org/abs/2110.08559?context=cs
Github: https://github.com/moussaKam/FrugalScore
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3674/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3673/comments | https://api.github.com/repos/huggingface/datasets/issues/3673/events | https://github.com/huggingface/datasets/issues/3673 | 1,123,010,520 | I_kwDODunzps5C78fY | 3,673 | `load_dataset("snli")` is different from dataset viewer | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp... | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Yes, we decided to replace the encoded label with the corresponding label when possible in the dataset viewer. But\r\n1. maybe it's the wrong default\r\n2. we could find a way to show both (with a switch, or showing both ie. `0 (neutral)`).\r\n",
"Hi @severo,\r\n\r\nThanks for clarifying. \r\n\r\nI think this de... | 1,643,890,243,000 | 1,645,010,551,000 | 1,644,598,881,000 | NONE | null | null | null | ## Describe the bug
The dataset that is downloaded from the Hub via `load_dataset("snli")` is different from what is available in the dataset viewer. In the viewer the labels are not encoded (i.e., "neutral", "entailment", "contradiction"), while the downloaded dataset shows the encoded labels (i.e., 0, 1, 2).
Is this expected?
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 20.4
- Python version: 3.7
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3673/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3673/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3672/comments | https://api.github.com/repos/huggingface/datasets/issues/3672/events | https://github.com/huggingface/datasets/pull/3672 | 1,122,980,556 | PR_kwDODunzps4yBUrZ | 3,672 | Prioritize `module.builder_kwargs` over defaults in `TestCommand` | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,643,888,322,000 | 1,643,978,240,000 | 1,643,978,239,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3672",
"html_url": "https://github.com/huggingface/datasets/pull/3672",
"diff_url": "https://github.com/huggingface/datasets/pull/3672.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3672.patch",
"merged_at": 1643978239000
} | This fixes a bug in the `TestCommand` where multiple kwargs for `name` were passed if it was set in both default and `module.builder_kwargs`. Example error:
```Python
Traceback (most recent call last):
File "create_metadata.py", line 96, in <module>
main(**vars(args))
File "create_metadata.py", line 86, in main
metadata_command.run()
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 144, in run
for j, builder in enumerate(get_builders()):
File "/opt/conda/lib/python3.7/site-packages/datasets/commands/test.py", line 141, in get_builders
name=name, cache_dir=self._cache_dir, data_dir=self._data_dir, **module.builder_kwargs
TypeError: type object got multiple values for keyword argument 'name'
```
Let me know what you think. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3672/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3671/comments | https://api.github.com/repos/huggingface/datasets/issues/3671/events | https://github.com/huggingface/datasets/issues/3671 | 1,122,864,253 | I_kwDODunzps5C7Yx9 | 3,671 | Give an estimate of the dataset size in DatasetInfo | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,643,881,630,000 | 1,643,881,630,000 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Currently, only part of the datasets provide `dataset_size`, `download_size`, `size_in_bytes` (and `num_bytes` and `num_examples` inside `splits`). I would want to get this information, or an estimation, for all the datasets.
**Describe the solution you'd like**
- get access to the git information for the dataset files hosted on the hub
- look at the [`Content-Length`](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Length) for the files served by HTTP
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3671/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3670/comments | https://api.github.com/repos/huggingface/datasets/issues/3670/events | https://github.com/huggingface/datasets/pull/3670 | 1,122,439,827 | PR_kwDODunzps4x_kBx | 3,670 | feat: 🎸 generate info if dataset_infos.json does not exist | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"It's a first attempt at solving https://github.com/huggingface/datasets/issues/3013.",
"I only kept these ones:\r\n```\r\n path: str,\r\n data_files: Optional[Union[Dict, List, str]] = None,\r\n download_config: Optional[DownloadConfig] = None,\r\n download_mode: Optional[GenerateMode] = None,\r\n ... | 1,643,839,916,000 | 1,645,459,031,000 | 1,645,459,030,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3670",
"html_url": "https://github.com/huggingface/datasets/pull/3670",
"diff_url": "https://github.com/huggingface/datasets/pull/3670.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3670.patch",
"merged_at": 1645459030000
} | in get_dataset_infos(). Also: add the `use_auth_token` parameter, and create get_dataset_config_info()
✅ Closes: #3013 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3670/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3669/comments | https://api.github.com/repos/huggingface/datasets/issues/3669/events | https://github.com/huggingface/datasets/pull/3669 | 1,122,335,622 | PR_kwDODunzps4x_OTI | 3,669 | Common voice validated partition | {
"login": "shalymin-amzn",
"id": 98762373,
"node_id": "U_kgDOBeL-hQ",
"avatar_url": "https://avatars.githubusercontent.com/u/98762373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shalymin-amzn",
"html_url": "https://github.com/shalymin-amzn",
"followers_url": "https://api.github.com/users/shalymin-amzn/followers",
"following_url": "https://api.github.com/users/shalymin-amzn/following{/other_user}",
"gists_url": "https://api.github.com/users/shalymin-amzn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shalymin-amzn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shalymin-amzn/subscriptions",
"organizations_url": "https://api.github.com/users/shalymin-amzn/orgs",
"repos_url": "https://api.github.com/users/shalymin-amzn/repos",
"events_url": "https://api.github.com/users/shalymin-amzn/events{/privacy}",
"received_events_url": "https://api.github.com/users/shalymin-amzn/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @patrickvonplaten - could you please advise whether this would be a welcomed change, and if so, who I consult regarding the unit-tests?",
"I'd be happy with adding this change. @anton-l @lhoestq - what do you think?",
"Cool ! I just fixed the tests by adding a dummy `validated.tsv` file in the dummy data ar... | 1,643,832,283,000 | 1,644,341,212,000 | 1,644,340,992,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3669",
"html_url": "https://github.com/huggingface/datasets/pull/3669",
"diff_url": "https://github.com/huggingface/datasets/pull/3669.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3669.patch",
"merged_at": 1644340992000
} | This patch adds access to the 'validated' partitions of CommonVoice datasets (provided by the dataset creators but not available in the HuggingFace interface yet).
As 'validated' contains significantly more data than 'train' (although it contains both test and validation, so one needs to be careful there), it can be useful to train better models where no strict comparison with the previous work is intended. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3669/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3668/comments | https://api.github.com/repos/huggingface/datasets/issues/3668/events | https://github.com/huggingface/datasets/issues/3668 | 1,122,261,736 | I_kwDODunzps5C5Fro | 3,668 | Couldn't cast array of type string error with cast_column | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! I wasn't able to reproduce the error, are you still experiencing this ? I tried calling `cast_column` on a string column containing paths.\r\n\r\nIf you manage to share a reproducible code example that would be perfect",
"Hi,\r\n\r\nI think my team mate got this solved. Clolsing it for now and will reopen i... | 1,643,826,809,000 | 1,658,237,784,000 | 1,658,237,784,000 | NONE | null | null | null | ## Describe the bug
In OVH cloud during Huggingface Robust-speech-recognition event on a AI training notebook instance using jupyter lab and running jupyter notebook When using the dataset.cast_column("audio",Audio(sampling_rate=16_000))
method I get error

This was working with datasets version 1.17.1.dev0
but now with version 1.18.3 produces the error above.
## Steps to reproduce the bug
load dataset:

remove columns:

run my fix_path function.
This also creates the audio column that is referring to the absolute file path of the audio

Then I concatenate few other datasets and finally try the cast_column method
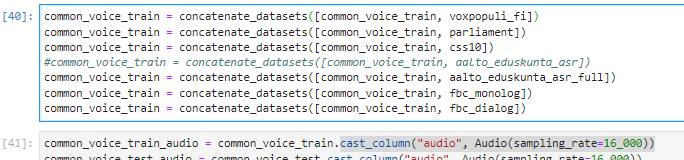
but get error:
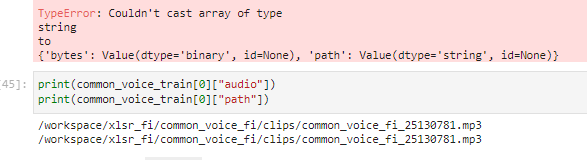
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3
- Platform:
OVH Cloud, AI Training section, container for Huggingface Robust Speech Recognition event image(baaastijn/ovh_huggingface)
- Python version: 3.8.8
- PyArrow version:
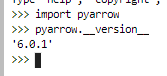
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3668/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3668/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3667/comments | https://api.github.com/repos/huggingface/datasets/issues/3667/events | https://github.com/huggingface/datasets/pull/3667 | 1,122,060,630 | PR_kwDODunzps4x-Ujt | 3,667 | Process .opus files with torchaudio | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | [
"Note that torchaudio is maybe less practical to use for TF or JAX users.\r\nThis is not in the scope of this PR, but in the future if we manage to find a way to let the user control the decoding it would be nice",
"> Note that torchaudio is maybe less practical to use for TF or JAX users. This is not in the scop... | 1,643,815,394,000 | 1,643,988,578,000 | 1,643,988,578,000 | CONTRIBUTOR | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3667",
"html_url": "https://github.com/huggingface/datasets/pull/3667",
"diff_url": "https://github.com/huggingface/datasets/pull/3667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3667.patch",
"merged_at": null
} | @anton-l suggested to proccess .opus files with `torchaudio` instead of `soundfile` as it's faster:

(moreover, I didn't manage to load .opus files with `soundfile` / `librosa` locally on any my machine anyway for some reason, even with `ffmpeg` installed).
For now my current changes work with locally stored file:
```python
# download sample opus file (from MultilingualSpokenWords dataset)
!wget https://huggingface.co/datasets/polinaeterna/test_opus/resolve/main/common_voice_tt_17737010.opus
from datasets import Dataset, Audio
audio_path = "common_voice_tt_17737010.opus"
dataset = Dataset.from_dict({"audio": [audio_path]}).cast_column("audio", Audio(48000))
dataset[0]
# {'audio': {'path': 'common_voice_tt_17737010.opus',
# 'array': array([ 0.0000000e+00, 0.0000000e+00, 3.0517578e-05, ...,
# -6.1035156e-05, 6.1035156e-05, 0.0000000e+00], dtype=float32),
# 'sampling_rate': 48000}}
```
But it doesn't work when loading inside s dataset from bytes (I checked on [MultilingualSpokenWords](https://github.com/huggingface/datasets/pull/3666), the PR is a draft now, maybe the bug is somewhere there )
```python
import torchaudio
with open(audio_path, "rb") as b:
print(torchaudio.load(b))
# RuntimeError: Error loading audio file: failed to open file <in memory buffer>
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3667/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3666/comments | https://api.github.com/repos/huggingface/datasets/issues/3666/events | https://github.com/huggingface/datasets/pull/3666 | 1,122,058,894 | PR_kwDODunzps4x-ULz | 3,666 | process .opus files (for Multilingual Spoken Words) | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq I still have problems with processing `.opus` files with `soundfile` so I actually cannot fully check that it works but it should... Maybe this should be investigated in case of someone else would also have problems with that.\r\n\r\nAlso, as the data is in a private repo on the hub (before we come to a ... | 1,643,815,308,000 | 1,645,524,243,000 | 1,645,524,233,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3666",
"html_url": "https://github.com/huggingface/datasets/pull/3666",
"diff_url": "https://github.com/huggingface/datasets/pull/3666.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3666.patch",
"merged_at": 1645524233000
} | Opus files requires `libsndfile>=1.0.30`. Add check for this version and tests.
**outdated:**
Add [Multillingual Spoken Words dataset](https://mlcommons.org/en/multilingual-spoken-words/)
You can specify multiple languages for downloading 😌:
```python
ds = load_dataset("datasets/ml_spoken_words", languages=["ar", "tt"])
```
1. I didn't take into account that each time you pass a set of languages the data for a specific language is downloaded even if it was downloaded before (since these are custom configs like `ar+tt` and `ar+tt+br`. Maybe that wasn't a good idea?
2. The script will have to be slightly changed after merge of https://github.com/huggingface/datasets/pull/3664
2. Just can't figure out what wrong with dummy files... 😞 Maybe we should get rid of them at some point 😁 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3666/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3666/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3665/comments | https://api.github.com/repos/huggingface/datasets/issues/3665/events | https://github.com/huggingface/datasets/pull/3665 | 1,121,753,385 | PR_kwDODunzps4x9TnU | 3,665 | Fix MP3 resampling when a dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,643,797,905,000 | 1,643,799,146,000 | 1,643,799,146,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3665",
"html_url": "https://github.com/huggingface/datasets/pull/3665",
"diff_url": "https://github.com/huggingface/datasets/pull/3665.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3665.patch",
"merged_at": 1643799145000
} | The resampler needs to be updated if the `orig_freq` doesn't match the audio file sampling rate
Fix https://github.com/huggingface/datasets/issues/3662 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3665/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3664/comments | https://api.github.com/repos/huggingface/datasets/issues/3664/events | https://github.com/huggingface/datasets/pull/3664 | 1,121,233,301 | PR_kwDODunzps4x7mg_ | 3,664 | [WIP] Return local paths to Common Voice | {
"login": "anton-l",
"id": 26864830,
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anton-l",
"html_url": "https://github.com/anton-l",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"repos_url": "https://api.github.com/users/anton-l/repos",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Cool thanks for giving it a try @anton-l ! \r\n\r\nWould be very much in favor of having \"real\" paths to the audio files again for non-streaming use cases. At the same time it would be nice to make the audio data loading script as understandable as possible so that the community can easily add audio datasets in ... | 1,643,752,107,000 | 1,645,521,246,000 | 1,645,521,246,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3664",
"html_url": "https://github.com/huggingface/datasets/pull/3664",
"diff_url": "https://github.com/huggingface/datasets/pull/3664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3664.patch",
"merged_at": null
} | Fixes https://github.com/huggingface/datasets/issues/3663
This is a proposed way of returning the old local file-based generator while keeping the new streaming generator intact.
TODO:
- [ ] brainstorm a bit more on https://github.com/huggingface/datasets/issues/3663 to see if we can do better
- [ ] refactor the heck out of this PR to avoid completely copying the logic between the two generators | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3664/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3664/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3663/comments | https://api.github.com/repos/huggingface/datasets/issues/3663/events | https://github.com/huggingface/datasets/issues/3663 | 1,121,067,647 | I_kwDODunzps5C0iJ_ | 3,663 | [Audio] Path of Common Voice cannot be used for audio loading anymore | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Having talked to @lhoestq, I see that this feature is no longer supported. \r\n\r\nI really don't think this was a good idea. It is a major breaking change and one for which we don't even have a working solution at the moment, which is bad for PyTorch as we don't want to force people to have `datasets` decode audi... | 1,643,740,810,000 | 1,663,772,589,000 | 1,663,772,182,000 | MEMBER | null | null | null | ## Describe the bug
## Steps to reproduce the bug
```python
from datasets import load_dataset
from torchaudio import load
ds = load_dataset("common_voice", "ab", split="train")
# both of the following commands fail at the moment
load(ds[0]["audio"]["path"])
load(ds[0]["path"])
```
## Expected results
The path should be the complete absolute path to the downloaded audio file not some relative path.
## Actual results
```bash
~/hugging_face/venv_3.9/lib/python3.9/site-packages/torchaudio/backend/sox_io_backend.py in load(filepath, frame_offset, num_frames, normalize, channels_first, format)
150 filepath, frame_offset, num_frames, normalize, channels_first, format)
151 filepath = os.fspath(filepath)
--> 152 return torch.ops.torchaudio.sox_io_load_audio_file(
153 filepath, frame_offset, num_frames, normalize, channels_first, format)
154
RuntimeError: Error loading audio file: failed to open file cv-corpus-6.1-2020-12-11/ab/clips/common_voice_ab_19904194.mp3
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.18.3.dev0
- Platform: Linux-5.4.0-96-generic-x86_64-with-glibc2.27
- Python version: 3.9.1
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3663/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3662/comments | https://api.github.com/repos/huggingface/datasets/issues/3662/events | https://github.com/huggingface/datasets/issues/3662 | 1,121,024,403 | I_kwDODunzps5C0XmT | 3,662 | [Audio] MP3 resampling is incorrect when dataset's audio files have different sampling rates | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks @lhoestq for finding the reason of incorrect resampling. This issue affects all languages which have sound files with different sampling rates such as Turkish and Luganda.",
"@cahya-wirawan - do you know how many languages have different sampling rates in Common Voice? I'm quite surprised to see this for ... | 1,643,738,104,000 | 1,643,799,145,000 | 1,643,799,145,000 | MEMBER | null | null | null | The Audio feature resampler for MP3 gets stuck with the first original frequencies it meets, which leads to subsequent decoding to be incorrect.
Here is a code to reproduce the issue:
Let's first consider two audio files with different sampling rates 32000 and 16000:
```python
# first download a mp3 file with sampling_rate=32000
!wget https://file-examples-com.github.io/uploads/2017/11/file_example_MP3_700KB.mp3
import torchaudio
audio_path = "file_example_MP3_700KB.mp3"
audio_path2 = audio_path.replace(".mp3", "_resampled.mp3")
resample = torchaudio.transforms.Resample(32000, 16000) # create a new file with sampling_rate=16000
torchaudio.save(audio_path2, resample(torchaudio.load(audio_path)[0]), 16000)
```
Then we can see an issue here when decoding:
```python
from datasets import Dataset, Audio
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[0] # decode the first audio file sets the resampler orig_freq to 32000
print(dataset .features["audio"]._resampler.orig_freq)
# 32000
print(dataset[0]["audio"]["array"].shape) # here decoding is fine
# (1308096,)
dataset = Dataset.from_dict({"audio": [audio_path, audio_path2]}).cast_column("audio", Audio(48000))
dataset[1] # decode the second audio file sets the resampler orig_freq to 16000
print(dataset .features["audio"]._resampler.orig_freq)
# 16000
print(dataset[0]["audio"]["array"].shape) # here decoding uses orig_freq=16000 instead of 32000
# (2616192,)
```
The value of `orig_freq` doesn't change no matter what file needs to be decoded
cc @patrickvonplaten @anton-l @cahya-wirawan @albertvillanova
The issue seems to be here in `Audio.decode_mp3`:
https://github.com/huggingface/datasets/blob/4c417d52def6e20359ca16c6723e0a2855e5c3fd/src/datasets/features/audio.py#L176-L180 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3662/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3661/comments | https://api.github.com/repos/huggingface/datasets/issues/3661/events | https://github.com/huggingface/datasets/pull/3661 | 1,121,000,251 | PR_kwDODunzps4x61ad | 3,661 | Remove unnecessary 'r' arg in | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The CI failure is only because of the datasets is missing some sections in their cards - we can ignore that since it's unrelated to this PR"
] | 1,643,736,567,000 | 1,644,253,047,000 | 1,644,249,762,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3661",
"html_url": "https://github.com/huggingface/datasets/pull/3661",
"diff_url": "https://github.com/huggingface/datasets/pull/3661.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3661.patch",
"merged_at": 1644249762000
} | Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3661/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3660/comments | https://api.github.com/repos/huggingface/datasets/issues/3660/events | https://github.com/huggingface/datasets/pull/3660 | 1,120,982,671 | PR_kwDODunzps4x6xr8 | 3,660 | Change HTTP links to HTTPS | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users/bryant1410/followers",
"following_url": "https://api.github.com/users/bryant1410/following{/other_user}",
"gists_url": "https://api.github.com/users/bryant1410/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bryant1410/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bryant1410/subscriptions",
"organizations_url": "https://api.github.com/users/bryant1410/orgs",
"repos_url": "https://api.github.com/users/bryant1410/repos",
"events_url": "https://api.github.com/users/bryant1410/events{/privacy}",
"received_events_url": "https://api.github.com/users/bryant1410/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,643,735,571,000 | 1,663,773,392,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3660",
"html_url": "https://github.com/huggingface/datasets/pull/3660",
"diff_url": "https://github.com/huggingface/datasets/pull/3660.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3660.patch",
"merged_at": null
} | I tested the links. I also fixed some typos.
Originally from #3489 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3660/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3660/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3659/comments | https://api.github.com/repos/huggingface/datasets/issues/3659/events | https://github.com/huggingface/datasets/issues/3659 | 1,120,913,672 | I_kwDODunzps5Cz8kI | 3,659 | push_to_hub but preview not working | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @thomas-happify, please note that the preview may take some time before rendering the data.\r\n\r\nI've seen it is already working.\r\n\r\nI close this issue. Please feel free to reopen it if the problem arises again."
] | 1,643,732,637,000 | 1,644,393,637,000 | 1,644,393,637,000 | NONE | null | null | null | ## Dataset viewer issue for '*happifyhealth/twitter_pnn*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/happifyhealth/twitter_pnn)*
I used
```
dataset.push_to_hub("happifyhealth/twitter_pnn")
```
but the preview is not working.
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3659/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3658/comments | https://api.github.com/repos/huggingface/datasets/issues/3658/events | https://github.com/huggingface/datasets/issues/3658 | 1,120,880,395 | I_kwDODunzps5Cz0cL | 3,658 | Dataset viewer issue for *P3* | {
"login": "jeffistyping",
"id": 22351555,
"node_id": "MDQ6VXNlcjIyMzUxNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/22351555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeffistyping",
"html_url": "https://github.com/jeffistyping",
"followers_url": "https://api.github.com/users/jeffistyping/followers",
"following_url": "https://api.github.com/users/jeffistyping/following{/other_user}",
"gists_url": "https://api.github.com/users/jeffistyping/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeffistyping/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeffistyping/subscriptions",
"organizations_url": "https://api.github.com/users/jeffistyping/orgs",
"repos_url": "https://api.github.com/users/jeffistyping/repos",
"events_url": "https://api.github.com/users/jeffistyping/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeffistyping/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The error is now:\r\n\r\n```\r\nStatus code: 400\r\nException: Status400Error\r\nMessage: this dataset is not supported for now.\r\n```\r\n\r\nWe've disabled the dataset viewer for several big datasets like this one. We hope being able to reenable it soon.",
"The list of splits cannot be obtained. cc... | 1,643,731,076,000 | 1,662,625,108,000 | null | NONE | null | null | null | ## Dataset viewer issue for '*P3*'
**Link: https://huggingface.co/datasets/bigscience/P3**
```
Status code: 400
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
```
Am I the one who added this dataset ? No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3658/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3657/comments | https://api.github.com/repos/huggingface/datasets/issues/3657/events | https://github.com/huggingface/datasets/pull/3657 | 1,120,602,620 | PR_kwDODunzps4x5f1I | 3,657 | Extend dataset builder for streaming in `get_dataset_split_names` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I'm impatient to see if it has an impact on the number of valid datasets for the dataset viewer. For the record, today:\r\n\r\n<img width=\"660\" alt=\"Capture d’écran 2022-02-01 à 14 32 19\" src=\"https://user-images.githubusercontent.com/1676121/151977579-b5a239d9-6662-4aeb-bfd1-eef6b8249991.png\">\r\n",
"Th... | 1,643,718,084,000 | 1,643,928,546,000 | 1,643,800,921,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3657",
"html_url": "https://github.com/huggingface/datasets/pull/3657",
"diff_url": "https://github.com/huggingface/datasets/pull/3657.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3657.patch",
"merged_at": 1643800921000
} | Currently, `get_dataset_split_names` doesn't extend a builder module to support streaming, even though it uses `StreamingDownloadManager` to download data. This PR fixes that.
To test the change, run the following:
```bash
pip install git+https://github.com/huggingface/datasets.git@fix-get_dataset_split_names-streaming
python -c "from datasets import get_dataset_split_names; print(get_dataset_split_names('facebook/multilingual_librispeech', 'german', download_mode='force_redownload', revision='137923f945552c6afdd8b60e4a7b43e3088972c1'))"
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3657/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3657/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3656/comments | https://api.github.com/repos/huggingface/datasets/issues/3656/events | https://github.com/huggingface/datasets/issues/3656 | 1,120,510,823 | I_kwDODunzps5CyaNn | 3,656 | checksum error subjqa dataset | {
"login": "RensDimmendaal",
"id": 9828683,
"node_id": "MDQ6VXNlcjk4Mjg2ODM=",
"avatar_url": "https://avatars.githubusercontent.com/u/9828683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RensDimmendaal",
"html_url": "https://github.com/RensDimmendaal",
"followers_url": "https://api.github.com/users/RensDimmendaal/followers",
"following_url": "https://api.github.com/users/RensDimmendaal/following{/other_user}",
"gists_url": "https://api.github.com/users/RensDimmendaal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RensDimmendaal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RensDimmendaal/subscriptions",
"organizations_url": "https://api.github.com/users/RensDimmendaal/orgs",
"repos_url": "https://api.github.com/users/RensDimmendaal/repos",
"events_url": "https://api.github.com/users/RensDimmendaal/events{/privacy}",
"received_events_url": "https://api.github.com/users/RensDimmendaal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @RensDimmendaal, \r\n\r\nI'm sorry but I can't reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset(\"subjqa\", \"electronics\")\r\nDownloading builder script: 9.15kB [00:00, 4.10MB/s] ... | 1,643,712,813,000 | 1,644,490,619,000 | 1,644,490,598,000 | NONE | null | null | null | ## Describe the bug
I get a checksum error when loading the `subjqa` dataset (used in the transformers book).
## Steps to reproduce the bug
```python
from datasets import load_dataset
subjqa = load_dataset("subjqa","electronics")
```
## Expected results
Loading the dataset
## Actual results
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-2-d2857d460155> in <module>()
2 from datasets import load_dataset
3
----> 4 subjqa = load_dataset("subjqa","electronics")
3 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://github.com/lewtun/SubjQA/archive/refs/heads/master.zip']
```
## Environment info
Google colab
- `datasets` version: 1.18.2
- Platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3656/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3655/comments | https://api.github.com/repos/huggingface/datasets/issues/3655/events | https://github.com/huggingface/datasets/issues/3655 | 1,119,801,077 | I_kwDODunzps5Cvs71 | 3,655 | Pubmed dataset not reachable | {
"login": "abhi-mosaic",
"id": 77638579,
"node_id": "MDQ6VXNlcjc3NjM4NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/77638579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhi-mosaic",
"html_url": "https://github.com/abhi-mosaic",
"followers_url": "https://api.github.com/users/abhi-mosaic/followers",
"following_url": "https://api.github.com/users/abhi-mosaic/following{/other_user}",
"gists_url": "https://api.github.com/users/abhi-mosaic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhi-mosaic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhi-mosaic/subscriptions",
"organizations_url": "https://api.github.com/users/abhi-mosaic/orgs",
"repos_url": "https://api.github.com/users/abhi-mosaic/repos",
"events_url": "https://api.github.com/users/abhi-mosaic/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhi-mosaic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @abhi-mosaic, thanks for reporting.\r\n\r\nI'm looking at it... ",
"also hitting this issue",
"Hey @albertvillanova, sorry to reopen this... I can confirm that on `master` branch the dataset is downloadable now but it is still broken in streaming mode:\r\n\r\n```python\r\n >>> import datasets\r\n >>> pubmed... | 1,643,654,747,000 | 1,671,477,490,000 | 1,644,848,141,000 | CONTRIBUTOR | null | null | null | ## Describe the bug
Trying to use the `pubmed` dataset fails to reach / download the source files.
## Steps to reproduce the bug
```python
pubmed_train = datasets.load_dataset('pubmed', split='train')
```
## Expected results
Should begin downloading the pubmed dataset.
## Actual results
```
ConnectionError: Couldn't reach ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz (InvalidSchema("No connection adapters were found for 'ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/pubmed21n0865.xml.gz'"))
```
## Environment info
- `datasets` version: 1.18.2
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.2
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3655/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/3654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3654/comments | https://api.github.com/repos/huggingface/datasets/issues/3654/events | https://github.com/huggingface/datasets/pull/3654 | 1,119,717,475 | PR_kwDODunzps4x2kiX | 3,654 | Better TQDM output | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq I've created a notebook for you to see the difference: https://colab.research.google.com/drive/1by3EqnoKvC2p-yKW4lPDGOFOZHyGVyeQ?usp=sharing.\r\n\r\nFeel free to suggest better descriptions for the progress bars. \r\n\r\nIf everything looks good, think we can merge."
] | 1,643,649,763,000 | 1,643,903,734,000 | 1,643,903,733,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3654",
"html_url": "https://github.com/huggingface/datasets/pull/3654",
"diff_url": "https://github.com/huggingface/datasets/pull/3654.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3654.patch",
"merged_at": 1643903733000
} | This PR does the following:
* if `dataset_infos.json` exists for a dataset, uses `num_examples` to print the total number of examples that needs to be generated (in `builder.py`)
* fixes `tqdm` + multiprocessing in Jupyter Notebook/Colab (the issue stems from this commit in the `tqdm` repo: https://github.com/tqdm/tqdm/commit/f7722edecc3010cb35cc1c923ac4850a76336f82)
* adds the missing `drop_last_batch` and `with_ranks` params to `DatasetDict.map`
* correctly computes the number of iterations in `map` and the CSV/JSON loader when `batched=True` to fix `tqdm` progress bars
* removes the `bool(logging.get_verbosity() == logging.NOTSET)` (or simplifies `bool(logging.get_verbosity() == logging.NOTSET) or not utils.is_progress_bar_enabled()` to `not utils.is_progress_bar_enabled()`) condition and uses `utils.is_progress_bar_enabled` to check if `tqdm` output is enabled (this comment from @stas00 explains why the `bool(logging.get_verbosity() == logging.NOTSET)` check is problematic: https://github.com/huggingface/transformers/issues/14889#issue-1087318463)
Fix #2630 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3654/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3653/comments | https://api.github.com/repos/huggingface/datasets/issues/3653/events | https://github.com/huggingface/datasets/issues/3653 | 1,119,186,952 | I_kwDODunzps5CtXAI | 3,653 | `to_json` in multiprocessing fashion sometimes deadlock | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 1,643,621,707,000 | 1,643,621,707,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
`to_json` in multiprocessing fashion sometimes deadlock, instead of raising exceptions. Temporary solution is to see that it deadlocks, and then reduce the number of processes or batch size in order to reduce the memory footprint.
As @lhoestq pointed out, this might be related to https://bugs.python.org/issue22393#msg315684 where `multiprocessing` fails to raise the OOM exception. One suggested alternative is not use `concurrent.futures` instead.
## Steps to reproduce the bug
## Expected results
Script fails when one worker hits OOM, and raise appropriate error.
## Actual results
Deadlock
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.1
- Platform: Linux
- Python version: 3.8
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3653/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3652/comments | https://api.github.com/repos/huggingface/datasets/issues/3652/events | https://github.com/huggingface/datasets/pull/3652 | 1,118,808,738 | PR_kwDODunzps4xzinr | 3,652 | sp. Columbia => Colombia | {
"login": "serapio",
"id": 3781280,
"node_id": "MDQ6VXNlcjM3ODEyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3781280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/serapio",
"html_url": "https://github.com/serapio",
"followers_url": "https://api.github.com/users/serapio/followers",
"following_url": "https://api.github.com/users/serapio/following{/other_user}",
"gists_url": "https://api.github.com/users/serapio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/serapio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/serapio/subscriptions",
"organizations_url": "https://api.github.com/users/serapio/orgs",
"repos_url": "https://api.github.com/users/serapio/repos",
"events_url": "https://api.github.com/users/serapio/events{/privacy}",
"received_events_url": "https://api.github.com/users/serapio/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"The original openslr site mixed both names https://openslr.org/72/ :-)",
"Yeah, I filed the issue to have it fixed there last year, but it looks like they missed a few."
] | 1,643,589,663,000 | 1,644,425,725,000 | 1,643,617,747,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3652",
"html_url": "https://github.com/huggingface/datasets/pull/3652",
"diff_url": "https://github.com/huggingface/datasets/pull/3652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3652.patch",
"merged_at": 1643617747000
} | "Columbia" is various places in North America. The country is "Colombia". | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3652/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3651/comments | https://api.github.com/repos/huggingface/datasets/issues/3651/events | https://github.com/huggingface/datasets/pull/3651 | 1,118,597,647 | PR_kwDODunzps4xy3De | 3,651 | Update link in wiki_bio dataset | {
"login": "jxmorris12",
"id": 13238952,
"node_id": "MDQ6VXNlcjEzMjM4OTUy",
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jxmorris12",
"html_url": "https://github.com/jxmorris12",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url": "https://api.github.com/users/jxmorris12/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jxmorris12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jxmorris12/subscriptions",
"organizations_url": "https://api.github.com/users/jxmorris12/orgs",
"repos_url": "https://api.github.com/users/jxmorris12/repos",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"received_events_url": "https://api.github.com/users/jxmorris12/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> all the tests pass, but I'm still not able to import the dataset\r\n\r\nSince it's not merged on `master` yet, you have to provide the path to your local `wiki_bio.py` to use it.\r\nIndeed the library downloads the dataset files from `master` if you have a dev installation of the library.\r\n\r\nI agree it would... | 1,643,560,134,000 | 1,643,640,648,000 | 1,643,618,289,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3651",
"html_url": "https://github.com/huggingface/datasets/pull/3651",
"diff_url": "https://github.com/huggingface/datasets/pull/3651.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3651.patch",
"merged_at": 1643618289000
} | Fixes #3580 and makes the wiki_bio dataset work again. I changed the link and some documentation, and all the tests pass. Thanks @lhoestq for uploading the dataset to the HuggingFace data bucket.
@lhoestq -- all the tests pass, but I'm still not able to import the dataset, as the old Google Drive link is cached somewhere:
```python
>>> from datasets import load_dataset
load_dataset("wiki_bio>>> load_dataset("wiki_bio")
Using custom data configuration default
Downloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to /home/jxm3/.cache/huggingface/datasets/wiki_bio/default/1.1.0/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...
Traceback (most recent call last):
...
File "/home/jxm3/random/datasets/src/datasets/utils/file_utils.py", line 612, in get_from_cache
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil
```
what do I have to do to invalidate the cache and actually import the dataset? It's clearly set up correctly, since the data is downloaded and processed by the tests.
As an aside, this caching-loading-scripts behavior makes for a really bad developer experience. I just wasted an hour trying to figure out where the caching was happening and how to disable it, and I don't know. All I wanted to do was update the link and submit a pull request! I recommend that you all either change this behavior (i.e. updating the link to a dataset should "just work") or document it, since I couldn't find any information about this in the contributing.md or readme or anywhere else! Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3651/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3650/comments | https://api.github.com/repos/huggingface/datasets/issues/3650/events | https://github.com/huggingface/datasets/pull/3650 | 1,118,537,429 | PR_kwDODunzps4xyr2o | 3,650 | Allow 'to_json' to run in unordered fashion in order to lower memory footprint | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @thomasw21, I remember suggesting `imap_unordered` to @lhoestq at that time to speed up `to_json` further but after trying `pool_imap` on multiple datasets (>9GB) , memory utilisation was almost constant and we decided to go ahead with that only. \r\n\r\n1. Did you try this without `gzip`? Because `gzip` featu... | 1,643,548,999,000 | 1,657,120,790,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3650",
"html_url": "https://github.com/huggingface/datasets/pull/3650",
"diff_url": "https://github.com/huggingface/datasets/pull/3650.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3650.patch",
"merged_at": null
} | I'm using `to_json(..., num_proc=num_proc, compressiong='gzip')` with `num_proc>1`. I'm having an issue where things seem to deadlock at some point. Eventually I see OOM. I'm guessing it's an issue where one process starts to take a long time for a specific batch, and so other process keep accumulating their results in memory.
In order to flush memory, I propose we use optional `imap_unordered`. This will prevent one process to block the other ones. The logical thinking is that index are rarily relevant, and in one wants to keep an index, one can still create another column and reconstruct from there. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3650/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3649/comments | https://api.github.com/repos/huggingface/datasets/issues/3649/events | https://github.com/huggingface/datasets/issues/3649 | 1,117,502,250 | I_kwDODunzps5Cm7sq | 3,649 | Add IGLUE dataset | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608944167,
... | open | false | null | [] | null | [] | 1,643,381,981,000 | 1,643,382,155,000 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** IGLUE
- **Description:** IGLUE brings together 4 vision-and-language tasks across 20 languages (Twitter [thread](https://twitter.com/ebugliarello/status/1487045497583976455?s=20&t=SB4LZGDhhkUW83ugcX_m5w))
- **Paper:** https://arxiv.org/abs/2201.11732
- **Data:** https://github.com/e-bug/iglue
- **Motivation:** This dataset would provide a nice example of combining the text and image features of `datasets` together for multimodal applications.
Note: the data / code are not yet visible on the GitHub repo, so I've pinged the authors for more information.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3649/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/3648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3648/comments | https://api.github.com/repos/huggingface/datasets/issues/3648/events | https://github.com/huggingface/datasets/pull/3648 | 1,117,465,505 | PR_kwDODunzps4xvXig | 3,648 | Fix Windows CI: bump python to 3.7 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,643,379,894,000 | 1,643,380,839,000 | 1,643,380,839,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3648",
"html_url": "https://github.com/huggingface/datasets/pull/3648",
"diff_url": "https://github.com/huggingface/datasets/pull/3648.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3648.patch",
"merged_at": 1643380839000
} | Python>=3.7 is needed to install `tokenizers` 0.11 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3648/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3647/comments | https://api.github.com/repos/huggingface/datasets/issues/3647/events | https://github.com/huggingface/datasets/pull/3647 | 1,117,383,675 | PR_kwDODunzps4xvGDQ | 3,647 | Fix `add_column` on datasets with indices mapping | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Sure, let's include this in today's release.",
"Cool ! The windows CI should be fixed on master now, feel free to merge :)"
] | 1,643,375,189,000 | 1,643,384,158,000 | 1,643,384,158,000 | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3647",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"merged_at": 1643384157000
} | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3647/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3646/comments | https://api.github.com/repos/huggingface/datasets/issues/3646/events | https://github.com/huggingface/datasets/pull/3646 | 1,116,544,627 | PR_kwDODunzps4xsX66 | 3,646 | Fix streaming datasets that are not reset correctly | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Works smoothly with the `transformers.Trainer` class now, thank you!"
] | 1,643,304,062,000 | 1,643,387,669,000 | 1,643,387,668,000 | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3646",
"html_url": "https://github.com/huggingface/datasets/pull/3646",
"diff_url": "https://github.com/huggingface/datasets/pull/3646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3646.patch",
"merged_at": 1643387668000
} | Streaming datasets that use `StreamingDownloadManager.iter_archive` and `StreamingDownloadManager.iter_files` had some issues. Indeed if you try to iterate over such dataset twice, then the second time it will be empty.
This is because the two methods above are generator functions. I fixed this by making them return iterables that are reset properly instead.
Close https://github.com/huggingface/datasets/issues/3645
cc @anton-l | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3646/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/3645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3645/comments | https://api.github.com/repos/huggingface/datasets/issues/3645/events | https://github.com/huggingface/datasets/issues/3645 | 1,116,541,298 | I_kwDODunzps5CjRFy | 3,645 | Streaming dataset based on dl_manager.iter_archive/iter_files are not reset correctly | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [] | 1,643,303,861,000 | 1,643,387,668,000 | 1,643,387,668,000 | MEMBER | null | null | null | Hi ! When iterating over a streaming dataset once, it's not reset correctly because of some issues with `dl_manager.iter_archive` and `dl_manager.iter_files`. Indeed they are generator functions (so the iterator that is returned can be exhausted). They should be iterables instead, and be reset if we do a for loop again:
```python
from datasets import load_dataset
d = load_dataset("common_voice", "ab", split="test", streaming=True)
i = 0
for i, _ in enumerate(d):
pass
print(i) # 8
# let's do it again
i = 0
for i, _ in enumerate(d):
pass
print(i) # 0
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3645/timeline | null | completed | false |
End of preview. Expand
in Data Studio
No dataset card yet
- Downloads last month
- 13